




















Just a week after ChatGPT’s launch in November 2022, it had gained over a million followers. Two months later, about 100 million monthly active users were on it, making the chatbot the fastest growing consumer application in history and surpassing the launches of other popular apps such as TikTok and Instagram. Some of the world’s largest companies such as Shopify and Coca-Cola have announced plans for using ChatGPT. The explosive popularity of ChatGPT can be traced to the ease with which people can converse with the chatbot to answer questions and help them with tasks such as writing essays, emails and cover letters for jobs.
The widespread use of ChatGPT, developed by OpenAI, has brought to the forefront the underlying system that makes it so human-like and easy to use, namely large language models (LLMs). An LLM is an AI language model that generates human-like responses to text-based prompts. LLMs are still relatively new in the AI landscape, so let’s take a closer look at what they are and what they have to offer companies today.
An LLM involves an algorithm that has been trained on a large amount of text-based data to return answers to prompts based on relationships between different words. The model is able to learn new skills such as drafting presentations and writing code based on its analysis of this vast volume of data. In addition to ChatGPT, LLMs also drive AI tech such as Google’s Bard, Microsoft’s Bing, and Meta’s LLaMa.
What Are Large Language Models?
An LLM is a machine learning model that processes and generates human language from training on massive volumes of data. It uses a deep learning algorithm to learn the patterns and nuances of language and provide human-like responses to a wide variety of queries and prompts. LLMs can also learn new skills such as creative writing or sentiment analysis.
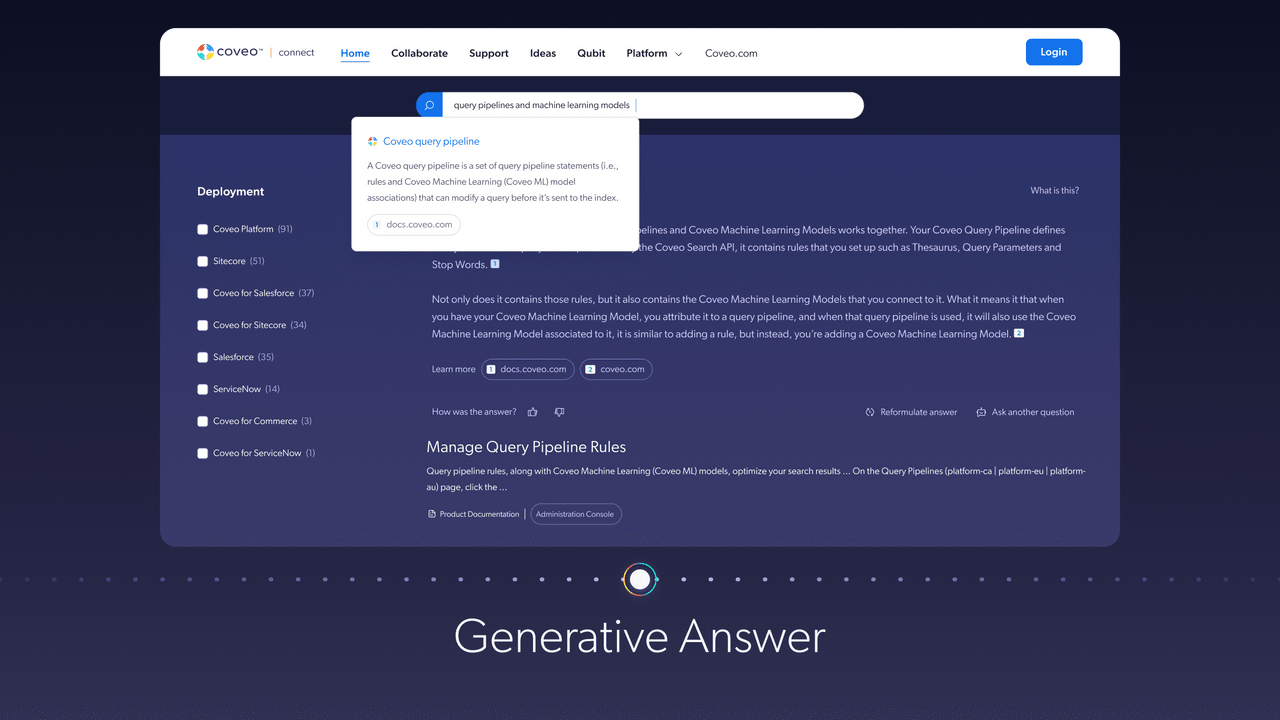
The “large” in its name refers to the size of the datasets on which it’s trained. The goal of an LLM at its core is to infer what comes next in a sequence of texts. ChatGPT is a conversational agent built on top of an LLM that can generate text in a way that’s extremely similar to humans. When it comes to expanding the search experience, Coveo is testing generative AI capabilities that surface answers directly within search results.
[NOTE: Unlike the brands mentioned above that train their models on data from the web, Coveo trains its LLM on private, enterprise content. ]
Large language models represent a significant advancement in an area of AI called natural language processing (NLP), which enables computers to process, understand and generate human language.
What Can Large Language Models Do?
The excitement around LLMs today revolves around their abilities to perform an impressive range of tasks that have the potential to significantly augment our lives. LLMs have gotten really good at performing tasks related to language that used to be reserved for humans, such as writing songs and summarizing a complex tax document, in mere seconds.
Here are a few of the powerful ways LLMs can be used today:
- Sentiment analysis: LLMs can take pieces of text, such as social media posts and customer reviews, and analyze their emotions and sentiments.
- Answering queries: LLMs can answer questions posed by humans in a human-like manner with natural language. They can also be trained on specific areas to help answer inquiries such as on a complex surgical procedure or how adoption works in a certain state.
- Language translation: They can translate texts effectively from one language to another.
- Summarization: Taking any long text-based content, such as complex tax codes or history lectures, LLMs can quickly provide a helpful overview.
- Text generation: LLMs can generate natural language texts in human-like ways in many applications including chatbots such as ChatGPT, virtual assistants in customer service and content creation for product teams and merchandisers.
One important characteristic that’s become apparent is LLMs can be unpredictable in their capabilities, meaning we do not know yet what future abilities they will display. AI researchers have been surprised at the new skills today’s most advanced LLMs have learned such as multiplication and computer coding.
How Do Large Language Models Work?
LLMs are trained on unlabeled data such as books, research papers and Wikipedia articles, to understand contextual data in language and to identify relationships between words. They use complex algorithms to process and analyze the data based on deep learning techniques such as a neural network.
The training involves feeding the model texts from which the model predicts the next word in a sequence. Over time, the model’s predictions get better based on how well it’s matching the actual next word. An LLM is trained until it reaches the level of accuracy and competency its programmers want to achieve. Based on their training, they are then able to respond to prompts by generating new text that effectively mimics human language.
How to Build Large Language Models
Let’s take a closer look at how to build a large language model at a high level:
Data Collection and Preprocessing
The first step in building a large language model is collecting a great deal of textual data on which the model will be trained. The text must then be “tokenized” or broken down into smaller units of data called tokens (e.g., “un,” “believe,” “able”) for easier processing and learning. Here are a few ways to tokenize programmatically.
Architecture
The next step is to choose the architecture for your model. A popular architecture for LLMs is called transformer, which uses a technique called self attention to keep track of relationships between words. Transformers analyze pieces of text concurrently, rather than one after the other as was previously the case, and allow machines to develop a sense of context between words. They have been pivotal as a way for LLMs to scale quickly and efficiently through faster and more cost effective training. A transformer architecture is behind OpenAI’s GPT-3 (Generative Pretrained Transformer).
Training
The model now must be trained on the text data to predict the next token in a sequence. Mathematical representations of text, called parameters, help the model learn the relationships between words and improve its performance. The more parameters a model processes, the better its performance in mimicking human language. For example, GPT-3 was trained on 175 billion parameters, making it 10 times larger than any predecessor.
Fine Tuning
Once training is complete, a process called fine tuning adjusts the model’s parameters to perform natural language tasks for specific industries or functions such as for scientific research or financial fraud detection. Fine tuning takes a pre-trained model and adjusts it to new data to achieve a certain level of performance without needing to start over.
What Are Risks of Large Language Models?
Concerns over the dangers of LLMs became evident in March this past year when 1,000 tech experts and leaders in AI, including Elon Musk, called in an open letter for the halting of work on advanced AI systems.
While LLMs can certainly produce an impressive range of answers and content in both human and computer languages, they make mistakes. The term “hallucinations” describes the tendency for an AI to generate answers to queries or prompts that appear correct but are actually wrong. LLMs also operate off of the data they’ve been trained on, which leads to many instances of delivering responses based on outdated information. There may also be inherent biases in its training data that skew responses in ways that are unhelpful or even damaging to humans.
In enterprise use cases, it’s not feasible to risk the errors and spreading of misinformation possible using LLMs. A big challenge for companies will be to ensure an LLM is generating content that is accurate and trustworthy. One way to mitigate risks is to make use of an LLM’s language capabilities while connecting the model to a reliable data source, such as a company’s education materials or website content.
Large Language Models and Search
When it comes to enterprise search, LLMs have the potential to significantly improve the search experience. For example, instead of getting back a page of results you must scan to get to your answer, as is today’s typical search experience, an LLM can respond with a single answer synthesized from a variety of sources in a conversational and easy-to-understand way.
An LLM can complement search, but does not replace it. It’s important to remember that engaging with an LLM like ChatGPT feels like search, but its answers are generated from its training data, which is fixed. Search, by contrast, draws from a database of the most up-to-date information. Additionally, we need ways to address LLMs’ hallucination and misinformation problems in search.
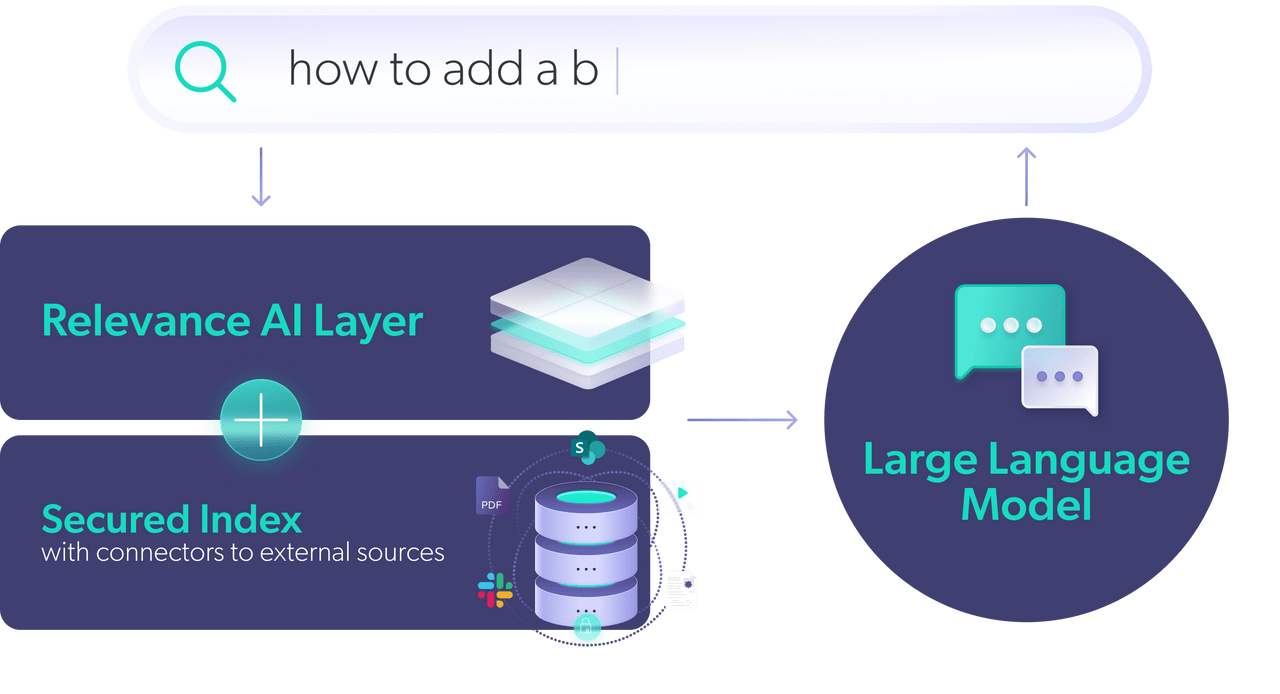
A way to achieve the intuitive experience of engaging with an LLM in a search experience is by using an LLM’s language generative abilities while depending on another system for information retrieval. Using something called Retrieval-Augmented Generation (RAG), AI researchers have shown a substantial reduction in hallucinations in conversational AI. The idea is to use a RAG to retrieve the most relevant information, rather than relying on a model’s fixed knowledge, while then feeding the information into an AI model to generate a coherent answer.
Last Thoughts
As LLMs get even better at conversational AI and data scientists are developing new applications to improve our lives, we will see them increasingly becoming a part of our existing systems including enterprise search. At Coveo, we believe LLMs are pivotal to the future of enterprise experiences and we’re hard at work building these conversational technologies to meet the high stakes needs of enterprise companies.