

A generative AI hallucination, also known as an LLM hallucination or AI hallucination, occurs when a large language model (LLM) used to generate output from an AI chatbot, search tool, or conversational AI application produces output that’s inaccurate, false, or misleading.
Things go awry with generative AI for various reasons. These include errors in the AI’s understanding or generation processes, overconfidence in its learned knowledge, training on data that doesn’t accurately represent the kind of tasks the AI is performing, and a lack of human oversight and feedback into AI output.
Understanding what generative AI hallucinations are and why they happen is important for companies who want to use artificial intelligence effectively and with confidence. A generative AI tool is only as good as its training data, AI algorithms, and generative model allow it to be. This underscores the critical role of human oversight in mitigating LLM hallucinations.
How Often Does AI Hallucinate?
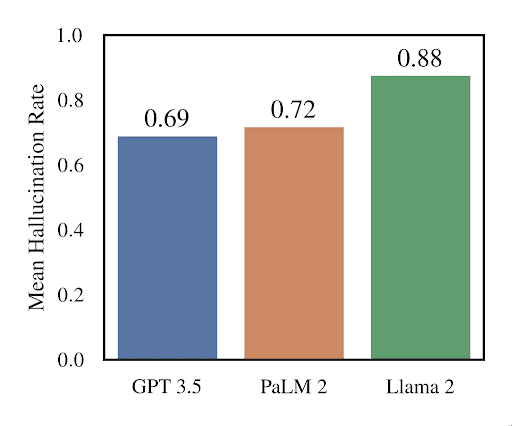
The short answer is: a lot. Hallucinations are a known generative AI risk that occurs with AI tools like OpenAI’s ChatGPT and Google’s Gemini. There’s no shortage of famously terrible AI generated hallucinations that serve as case studies for how LLM output can go awry.
Examples of AI Hallucinations
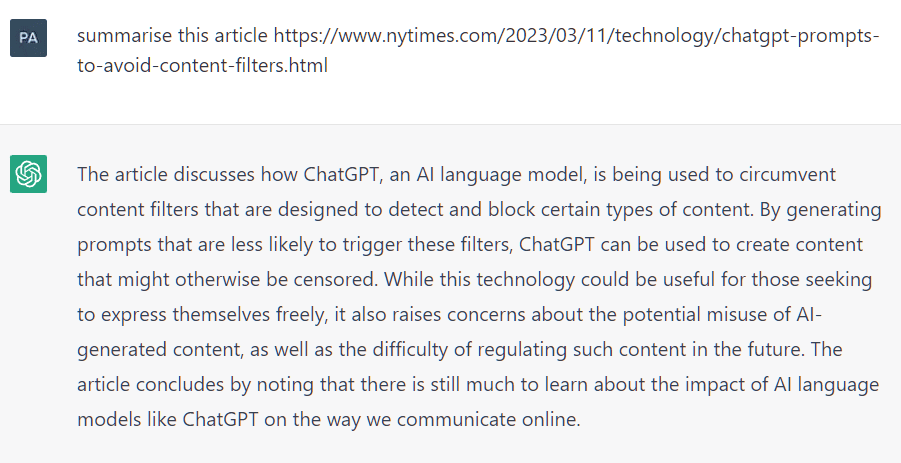
ChatGPT
For example, ChatGPT made up fake legal quotes and citations which were used in an actual court case. The unfortunate lawyers who submitted the false information were fined $5,000.
Gemini
When Google Gemini was introduced to the world as Bard, the genAI chatbot made up a “fact” about the James Webb Space Telescope during its livestream debut – an event attended by the media. Alphabet, Google’s parent company, lost $100 billion in market value after Reuter’s pointed out this inaccurate information.
Google faced significant backlash after Gemini’s image generation model produced historically inaccurate and culturally insensitive images, for example, by generating images of the Pope as a woman and a German-era Nazi with dark skin. These embarrassing AI hallucinations prompted Google to temporarily pause Gemini’s image generation feature so they could fix what they called a “fine-tuning” issue in the model’s programming. (Source)
When Google integrated Gemini into its search results in May 2024, the model spread equally alarming misinformation. For example, Gemini suggested that Barack Obama was Muslim, said that cats have the ability to teleport, and advised users that eating a rock a day was a good way to add vitamins and minerals to their diet. Gemini’s generative AI model also suggested removing film from a film-based camera to fix a jam (this method that would actually destroy any photos already taken.) (Source)
Amazon Q
And Amazon’s Q, another entry into the AI chatbot space, debuted with a thud when, three days after its release, Amazon employees warned it was prone to “severe hallucinations” and privacy concerns.
An AI chatbot like ChatGPT or Jasper AI operates thanks to the integration of various technologies including LLMs for text generation and comprehension, and natural language processing for interpreting and processing human language. Underpinning these functionalities are neural networks, which provide the computational framework for handling and analyzing the data.
What Causes AI Hallucinations?
There are inherent limitations in the way generative AI systems process and interpret information that cause hallucinations. These may manifest as:
False assumptions
LLMs make assumptions based on patterns they’ve seen during training and these assumptions make them prone to hallucinations. This happens because they learn to associate words in specific contexts (e.g., “Paris” is always associated with “France”). The genAI tool might incorrectly assume this pattern applies in all contexts, leading to errors when the context deviates from the norm.
Misinterpreting user intention
LLMs analyze user inputs based on word patterns and context, but lack a true understanding of human intentions or nuances. This can lead to situations where the model misinterprets the query, especially in complex, ambiguous, or nuanced scenarios, resulting in responses that lack factual accuracy or don’t align with the user’s actual intent.
Bias caused by training data
This is a big one — after all, garbage in, garbage out. LLMs learn from huge datasets that often contain cultural, linguistic, and political bias. The AI generated content it creates will naturally reflect this bias, and may contain unfair, false, skewed information, that’s rife with inconsistency.
Overconfidence
GenAI applications often seem incredibly confident in their responses. They’re designed to respond without doubt or emotion. LLMs generate text based on statistical likelihoods without the ability to cross-reference or verify information. This leads to assertive statements like Bard’s confident assertion that the James Webb Telescope took the “very first images of exoplanets.” (It didn’t.) These models don’t have a mechanism to express uncertainty or seek clarification that the text they produce contains accurate information.
An inability to reason
Unlike humans, LLMs don’t have true reasoning skills. They use pattern recognition and statistical correlations to generate a response. Without logical deduction or an understanding of causal relationships, a generative AI application is susceptible to generating nonsense, especially in situations that require a deep understanding of concepts or logical reasoning.
In an interview with the New York Times, ChatGPT’s former CEO Sam Altman affirmed that generative pre-trained transformers (GPTs) like ChatGPT are bad at reasoning and this is why they make stuff up. Per Altman:
“I would say the main thing they’re bad at is reasoning. And a lot of the valuable human things require some degree of complex reasoning. They’re good at a lot of other things — like, GPT-4 is vastly superhuman in terms of its world knowledge. It knows more than any human has ever known. On the other hand, again, sometimes it totally makes stuff up in a way that a human would not.”. On the other hand, again, sometimes it totally makes stuff up in a way that a human would not.”
How Can Organizations Mitigate the Risks Associated with AI Hallucinations?
Introducing a generative AI tool – and its potential for hallucinations – into your enterprise comes with some challenges. Public generative AI models in applications like ChatGPT pose huge privacy and security risks. For example, OpenAI may retain chat histories and other data to refine their models, potentially exposing your sensitive information to the public. They may also collect and retain user data like IP addresses, browser information, and browsing activities.
But using GenAI safely – and ensuring AI-generated content it produces is accurate, secure, and reliable – is possible. Here are some steps you can take to mitigate AI hallucinations and make AI output enterprise ready:
1. Create a secure environment
Responsible AI practices require that you establish a digital environment that adheres to specific security standards and incorporate principles of fairness, reliability, privacy, safety, and transparency. A responsible AI framework helps prevent unauthorized access and use of enterprise data.
You should operate your GenAI solution in a locked-down environment that complies with regulations like AICPA SOC 2 Type II, HIPAA, Cloud Security Alliance, and ISO 27001.
2. Unify access to your content
Most companies store information across multiple databases, tools, and systems — all of this contributes to your overall knowledge base. You can use content connectors to create a unified index of your important data from all possible content sources (Slack, Salesforce, your intranet, etc.).
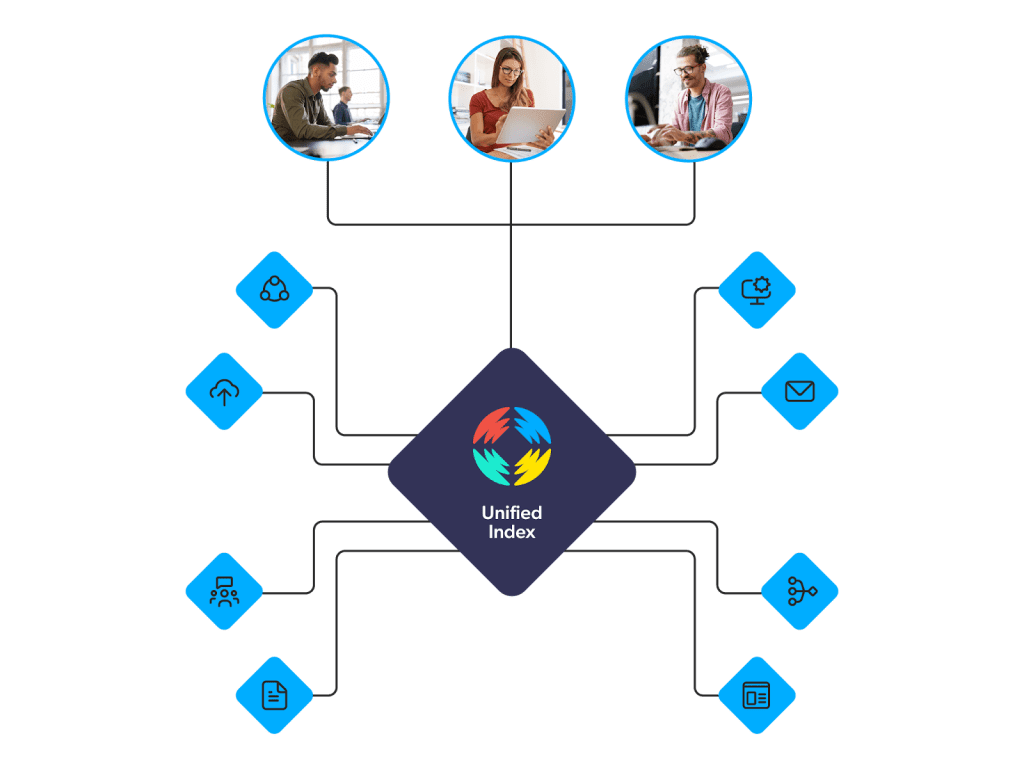
Unifying your content creates an expansive and searchable knowledge base that ensures outputs from AI models are comprehensive. Unifying content requires segmenting documents before routing them to the GenAI model, as we note in our ebook, Build vs Buy: 5 Generative AI Risks in CX & EX:
“This involves maximizing the segmentation of documents as part of the grounding context process before they are routed to the GenAI model. The LLM then provides a relevant response from these divided chunks of information, based specifically on your organization’s knowledge. This contextualization plays an essential role in the security of generative responses. It ensures that the results of the AI system are relevant, accurate, consistent and safe.”
Relevant reading: Chunking Information: Best Practices for Generative Experiences
3. Retain data ownership and control
Complete ownership and control over your data, including index and usage analytics, keeps proprietary information safe. Keep communication secure by using encryption protocols like HTTPS and TLS endpoints that provide authentication, confidentiality, and security. Implement an audit trail to understand how the AI model is being used so you can create guidelines that promote responsible, ethical use of the system.
4. Verify training data accuracy
Ensure the accuracy of training data and incorporate human intervention to validate the GenAI model’s outputs. Providing citations and links to source data introduces transparency and allows users to validate information for themselves.
Also, if your company hasn’t already, establish data cleaning best practices. This isn’t a call to boil the ocean: instead, use tools like usage analytics to identify the content that’s most useful for users or most helpful for self-service resolution, as some example metrics. From there, enterprises can identify what is next most helpful, and clean up that content. Check out our ebook, 6 Data Cleaning Best Practices for Enterprise AI Success.
5. Implement Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation, or RAG, is an AI framework that removes some of the limitations that tie an LLM to its training data. With RAG, an LLM can access updated knowledge and data based on a user query – a process called “grounding.” RAG gives companies greater control over what information can be used to answer a user query, pulling only the most relevant chunks from documents available in trusted internal sources and repositories.

6. Use the most up-to-date content
Regularly refresh, rescan, and rebuild content in content repositories across your enterprise so that the searchable content is current and relevant. These three update operations help maintain accurate GenAI outputs.
7. Provide a consistent user experience
If you’re using GenAI for search, chat, and other use cases, you need to provide consistent answers to users. A unified search engine is the answer to this challenge. An intelligent search platform like Coveo uses AI and machine learning to identify, surface, and generate results and answers from a unified index of all your content, which keeps information relevant, current, and consistent across your digital channels.
Leveraging Enterprise-Ready Generative AI
Understanding and mitigating the phenomenon of AI hallucinations in generative AI is the only way to make a GenAI system enterprise ready. Hallucinations pose significant risks to your reputation, your data security, and your peace of mind.
Coveo has over a decade of experience in enterprise-ready AI. The Coveo Platform provides a secure way for enterprises to harness GenAI while mitigating the risks of this innovative AI technology. Designed with security at its core, Coveo’s platform keeps generated content accurate, relevant, consistent, and safe.
Learn more about the customers achieving successful business outcomes with Coveo’s generative offering, and how you could be next!
Dig Deeper
Generative AI might be the current bell of the ball, but its far from the only AI model that can uplevel digital experiences. Explore our full suite of AI models in our free ebook, Generative AI and Top AI Models for CX.