
In today’s data-driven age, the volume of information and the ease of access to it is ever growing.
From consumers shopping at their favorite digital storefronts to video streaming services seeking to grow engagement, the need to get the right information quickly and effectively from the exponentially growing amount of data is critical to success. In the digital and internet age, tools such as search engines are essential in connecting people with information. Information retrieval systems also play a fundamental role in generative AI as the foundation for AI to access, process, and learn from data.
For enterprises, improving the relevance of search results and knowledge management can greatly impact the business, from growing the customer base to improving decision making. Advancements in information retrieval (IR) techniques can improve the experiences of customers, employees, and organizations.
An understanding of today’s top IR techniques will help prepare businesses seeking to enhance the experiences of their employees and customers.
Understanding Information Retrieval
Information retrieval is the process of obtaining relevant information from a collection of resources, such as documents, in the form of unstructured or semi-structured data.
It is made up of the techniques and algorithms used to effectively organize, retrieve and filter information for the purpose of answering a query. The purpose of information retrieval is to develop efficient ways of finding relevant information from large repositories and presenting them in an understandable way.

Information retrieval systems provide an interface between users and the information in data repositories. They allow us to make sense of the vast amounts of information we encounter daily. We encounter IR systems in the form of web search engines, virtual assistants, and sorting emails.

At a high level, key components of information retrieval are:
- Indexing: Data must first be organized in a way that is easy to search. Indexing involves extracting and analyzing the content and metadata of documents to create an index, which is a data structure optimized for quickly searching and retrieving information.
- Querying: An information retrieval process starts when a query enters the system. A query is a statement that a user makes to the system to request information. Queries may be simple keyword searches or in the form of natural language texts.
- Matching and ranking: Algorithms match the query against the indexed data and rank the results based on relevance or other ranking objectives (e.g., date, position, etc.).
- Retrieving: Once the data is matched, the system returns the relevant information to the user through a display or user interface.
From manual cataloging and archiving to today’s AI-powered search technologies, information retrieval has advanced greatly over the years. Relying on a variety of techniques and algorithms, an information retrieval system handles various challenges in a shifting landscape of information sources and types.
We next breakdown the main techniques and algorithms in use today.
Key Information Retrieval Techniques
Let’s take a look at the most common techniques in use today for information retrieval, their strengths and limitations, and real-world applications. Information retrieval systems often utilize a combination of these techniques to improve accuracy and efficiency.
Boolean Retrieval
One of the simplest methods, boolean retrieval involves retrieving information based on Boolean operations (AND, OR and NOT). This technique is an effective way to filter information and useful for its precision. A document is a match to the query or it is not. The Boolean method tends to be used by professionals who are searching for specific documents, such as legal searches.
While simple and efficient, a disadvantage of Boolean retrieval is there is no ranking of the results by how closely they match the needs of the user. There is also no nuance, meaning unless there is an exact match with the terms, the system will fail to retrieve results that share similarities with the query terms.
Vector Space Model
In contrast, a vector space model (VSM) has the ability to capture nuances and retrieve results with semantic similarities to the query. In this algebraic method, documents and queries are represented as vectors in multidimensional space. Each vector embedding contains the semantic meanings of the documents or queries they represent. By measuring the distance or angle between the vectors, a user can calculate the similarity between documents and queries (e.g., the similarity between “storm” and “rain”).
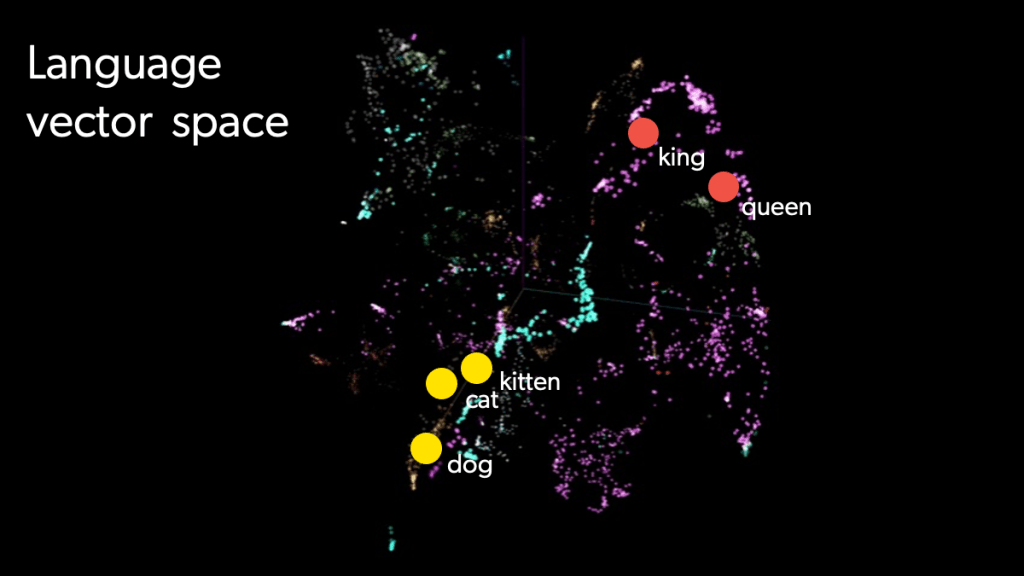
In this model, each term in a document earns a term weighting, which is a numerical value that reflects that term’s importance in the context of the document or query. Term weighting helps distinguish between common words, such as “and” and “the,” and rare words that might be more relevant.
Once the weights have been assigned, the cosine similarity, which measures the similarity between two vectors, determines a document’s relevance to a particular query. A higher cosine similarity indicates greater similarity between a document and query. The system then selects and ranks documents with the top scores.
In this way, the vector space model is useful for IR when it is important to retrieve and rank information that is the most relevant to the query. It’s widely used in search engines, enterprise search, recommendations and ecommerce. It is also foundational in natural language processing (NLP) to take text data and make it suitable for NLP tasks.
Probabilistic Models
There is a certain degree of uncertainty in any kind of information retrieval. For example, how well has the system understood the user’s information needs? How relevant is this document to the query? A probabilistic model is a framework that estimates how likely it is that a document is relevant to a query and ranks documents using those measurements. It is similar to a VSM in its use to rank documents by relevance, but probabilistic models are grounded in probability theory while VSMs rely on geometric similarities (cosine similarities) found through vector algebra.
The model employs the probability ranking principle (PRP) to rank documents in decreasing order of the probability of relevance to the query. The principle states that the best performance from a query will come from ranking the documents in order of their probability of relevance according to the information available in the system. Relevance probabilities are calculated using probability theory, usually on the basis of Bayes’ Theorem, a mathematical formula for determining the probability of an outcome based on the occurrence of a preceding event, also known as conditional probability.
There are some limitations to the PRP, including its assumption that each document’s relevance to the query is independent of other documents. The assumption disregards potential relationships between the documents that may affect the relevance of the results. In the real world, other factors often must be taken into account to meet users’ needs or intents, such as redundancies between documents and the diversity of results.
Latent Semantic Analysis
Based on natural language processing, latent semantic analysis (LSA) is a method that analyzes the relationships between documents and the terms they contain.
LSA uncovers the latent, or hidden, semantic structure and relationships in the terms within a set of documents, addressing challenges in information retrieval such as words that have multiple meanings (e.g., “bark” or “bow”) and different words that mean the same thing (e.g., “small” and “little”). It is particularly useful in keyword-based information retrieval by retrieving results that are semantically related to the query, even when missing the exact terms used in a query.
LSA uses a technique called dimensionality reduction to help uncover the hidden semantic relationships between words and ideas across a set of documents. Dimensionality reduction compresses the data in a dataset of terms and documents into a smaller number of dimensions by filtering out less important details and retaining the most important concepts.
This helps focus the retrieval on the most meaningful patterns and relationships in the data.
Neural Information Retrieval Models
Advances in machine learning and deep learning have accelerated the field of information retrieval.
One area seeing strong success is neural information retrieval models, which use deep learning techniques to capture nuanced semantic relationships between documents and queries. These models are able to use deep neural networks to improve the accuracy and relevance of searches in large-scale data sets. They represent an advance in information retrieval, outperforming traditional IR methods by possessing the ability to understand the context of language and handling complex queries.
Neural information retrieval models use artificial neural networks, interconnected layers of nodes designed after the human brain, to improve the ranking of results in response to a query. These models are trained on vast amounts of data to learn complex relationships and patterns in text data.
Using deep learning techniques such as convolutional neural networks (CNNs) and transformers, these neural models build representations of queries and documents and learn complex patterns in the data. They convert words, groups of words or entire documents into numerical vectors called embeddings that capture semantic relationships and help match queries with documents. Unlike other IR models we’ve discussed, they learn and improve over time as they are fed more data.
Despite their advantages, neural IR models are not widespread due to limitations such as requiring heavy computational resources and access to large amounts of training data to reach a satisfactory level of performance.
Advanced Algorithms in Information Retrieval
Information retrieval systems employ search algorithms to match users to relevant documents in an efficient way. We review the most significant algorithms below.
TF-IDF
A widely used statistical calculation in information retrieval, Term Frequency-Inverse Document Frequency (TF-IDF) is a measure of how important a term within a document is in a collection of documents. It gives each term a score that is proportional to the term’s frequency within a document offset by how frequently the word appears in the collection of documents as a whole.
Put more simply, TF-IDF gives greater importance to terms within a document that are rare overall. This scoring helps IR systems rank documents by their relevance to the query.
TF-IDF works by measuring the term frequency (TF), or how often a word appears in a document, and the inverse document frequency (IDF), which measures the word frequency across all documents and is higher when the word appears less often. Calculating the TF-IDF score for each word leads to the conversion of each document into a vector, which means two documents can be compared using cosine similarity (covered above).
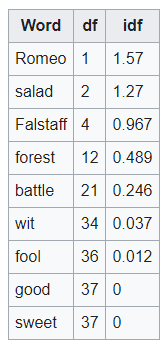
TF-IDF is also an important statistical method in textual analysis and NLP, which helps machines interpret human language, to determine how important a word is in a document compared to other documents. It has been shown to be effective in NLP tasks involving search engines and keyword extraction. Other applications could include classifying a document by category, analyzing the sentiment in a text by frequency of words, or summarizing text.
While popular for its simplicity, TF-IDF cannot help with semantic meaning and relationships between words, which are often important to the success of information retrieval.
BM-25
Best Matching 25 (BM-25) is a ranking algorithm and one of the most widely used of the probabilistic ranking method. It extends TF-IDF with additional parameters designed to introduce more flexibility and improvements to ranking scores with frequency saturation and document length.
This mean in addition to term frequency and inverse document frequency (TF-IDF), the algorithm:
- Adds a saturated frequency function to term frequency so that the relevance of a term increases at a decreasing rate, preventing the frequency of a term from taking over the relevancy ranking.
- Normalizes term frequency by document length to correct for documents that contain more terms because they are longer. To accomplish this, the formula incorporates the number of words in the document along with the average document length across the collection.
The algorithm introduces greater flexibility into the system by using two adjustable parameters to control the degree to which term frequency and document length affect the ranking score. BM-25 is more dynamic than TF-IDF because it’s able to adjust the ranking according to the type of query or collections of documents.
Its simplicity and effectiveness as a ranking function has made BM-25 popular in a variety of information retrieval applications including keyword search, calculating relevance scores and ranking documents. Many popular search engines use BM-25 along with enterprise search and ecommerce sites for product recommendations.
While foundational to keyword-based searches, it’s not as useful in more complex queries where semantic nuances in text are important.
PageRank and HITS
When it comes to web search engines, ranking algorithms play a fundamental role in determining the relevance of web pages to a user’s search. One of the best known is Google PageRank, a core component of the Google search engine developed by Google co-founders Larry Page and Sergey Brin in 1996.
It is a link-based ranking algorithm built on the idea of citations in academic research that gives more weight of importance to a webpage by the number and quality of websites that link to the page. Previous to PageRank, webpages were matched to searches through keywords, which were prone to manipulation for higher search rankings. PageRank changed the way web search works by introducing link analysis into the ranking of pages. The algorithm assigns a numerical value to each page based on the number and quality of incoming links, with higher scores indicating greater relevance.
Another major link-based algorithm, Hyperlink-Induced Topic Search (HITS), was a precursor to PageRank and influenced its development. HITS analyzes the link structure between web pages through a “hubs and authorities” algorithm to rank them.
It assigns two scores to each page: an authority score that is higher when the page is linked to by many other pages (meaning it’s a good information source) and a hubs score that is higher when the page has links to many authoritative pages (meaning it’s a good resource).
HITS is useful for finding pages dedicated to specific topics. It is query-dependent, basing its calculations on a subset of the web graph that’s relevant to the query, while PageRank is query-independent, operating on the entire web graph.
Eventually, PageRank emerged as the dominant ranking algorithm for search engines because it was easier to scale, not as vulnerable to manipulation and benefited from the commercial success of Google.
Neural Ranking Models
Advances in AI have led to the creation of a new class of ranking algorithms called neural ranking models, bringing with them a deeper and more nuanced understanding of user intent, context and semantics to the ranking task.
By utilizing interconnected neural networks that learn from data (deep learning), these models are able to handle much more complex relevance estimations between the query and documents and improve the ranking of search results.
Google’s BERT (Bidirectional Encoder Representations from Transformers) and OpenAI’s GPT (Generative Pre-trained Transformer) are two leading language models that are advancing matching documents to queries.
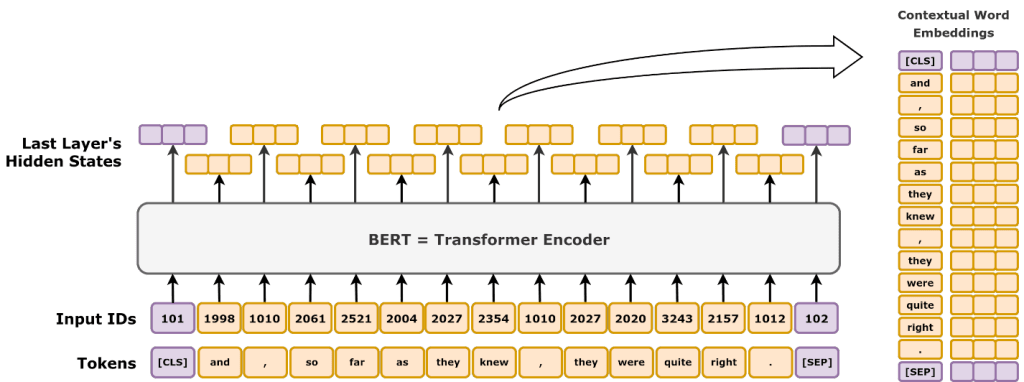
BERT is a bidirectional model that can capture the meaning of words with high accuracy by understanding the context of words in a sentence from left to right and right to left. BERT can improve the match between a query and documents by understanding the broader context of a word. It can be used together with a more traditional model to refine search results to fine-tune rankings for context and after capturing a fuller meaning of a word.
GPT, as we’ve seen in ChatGPT, generates human-like text and can suggest alternative queries that might better match the user’s intent or can directly answer users with concise language after completing document retrieval. This can be particularly helpful in environments using chatbots and virtual assistants.
Practical Applications of IR Techniques
Information retrieval techniques are essential across various industries and applications to help users find the information they are looking for quickly and efficiently.
- Ecommerce: Information retrieval is an important part of the shopping experience, helping customers find the right products for their needs. IR techniques that use AI can enhance product search by understanding the intent behind the user’s query without the need to exactly match the product to the words used in the query.
IR techniques can also provide product recommendations to users based on their past orders, browsing history and profile information. By helping to generate more relevant results, these methods can increase the chances of a browsing user becoming a customer. - Enterprise search: Organizations use enterprise search to retrieve information from the many different stores of data across the business. IR techniques are valuable in retrieving documents for employees efficiently, which improves productivity and saves valuable time by helping employees find what they are looking for quickly.
They are also essential to knowledge management and sharing knowledge in the organization, which improves collaboration and decision-making. Some IR systems provide advanced enterprise searching capabilities that allow for complex and sophisticated queries that are answered with precision and accuracy in the results. - Customer service: Information retrieval techniques enhance customer service by giving support teams the ability to quickly find information to assist customers.
IR also improves customer self-service by helping to provide real-time and contextually relevant responses without human involvement, such as in the form of generative answering. These IR systems can retrieve information from FAQs and product manuals for a satisfying customer experience.
Challenges and Future Directions
While rapidly developing and full of promise, advanced information retrieval techniques face challenges in their implementation. For techniques involving machine learning and deep learning, there are problems with scalability and efficiency since they require training on large datasets and significant computational resources, which can get very expensive.
Additionally, there are ethical considerations with integrating AI into information retrieval such as data privacy since these systems often access user data to personalize and improve results. Guidelines and compliance with privacy regulations, such as GDPR, along with taking security measures are important.
AI can also act on biases inherent in its training data, leading to discriminatory or skewed results. Mitigating bias to ensure fair outcomes is crucial. As IR techniques grow in complexity, it becomes harder to follow how they are working. This lack of transparency can be a barrier to trust and adoption. Developing methods to explain the results from complex techniques is one way to improve transparency.
Future directions in information retrieval involve further combining AI and semantic techniques with traditional techniques and the development of frameworks for transparency and fairness.
Conclusion
With the great volumes of data being generated everyday through the internet and within our workplaces, information retrieval systems are essential to making vast amounts of information available and accessible.
As IR techniques grow and evolve, businesses can use the combination of techniques that lead to the best relevancy results and collaboration across the organization. Utilizing advanced IR solutions that use AI to learn from data, make contextually relevant rankings and bring greater efficiency and accuracy to information retrieval will help your organization stay competitive moving forward in today’s data-driven landscape.
Learn about how Coveo’s advanced search solutions can help your organization get ahead.
Dig Deeper
Still researching what AI search platform fits your enterprise best? Grab your free copy of our Buyer’s Guide for Best Enterprise Search Engine, where you’ll find key considerations to evaluating enterprise search (aka information retrieval) software.






