

When people need information, they turn to search. Today 42% of consumers go straight to a company’s website or help center when they need info. How you architect and orchestrate that search experience can be the difference between a frictionless journey and one full of frustration.
Much of the quality, accuracy, and relevance of your search experience comes down to indexing. Indexing supports better navigation, product discovery, and personalization. Two important components comprise nearly any search index:
- Query pipeline
- Indexing pipeline
Our focus for this blog post will be an exploration of the latter. What is an indexing pipeline, how to use it, and the benefits your users (and your enterprise) can expect.
Relevant Reading: How Does an Enterprise Search Engine Work?
Indexing Pipelines vs. Query Pipelines: What’s the Difference?
At a fundamental level, a query pipeline processes user queries, applying different parameters and rules to shape how search results are then delivered. This typically happens across four steps:
Stages of the Query Pipeline:
- Preprocessing: Clean raw user queries (remove stop words and stemming, for example).
- Understanding: Analyze queries to understand intent using entity recognition, topic modeling, and other tasks.
- Retrieval: Search indexed data, which can involve ranking relevant documents or chunks of content and the use of a vector database.
- Response generation: Trigger necessary calculations and data aggregation and use a large language model (LLM) to generate responses.
The applications for query pipelines include search engines, chatbots, virtual assistants, and recommendations. The common book library makes for a suitable analogy: if a query pipeline is the process of using a library catalog to find a specific book — inputting title, author, genre, and so on — then the indexing pipeline is the catalog itself.
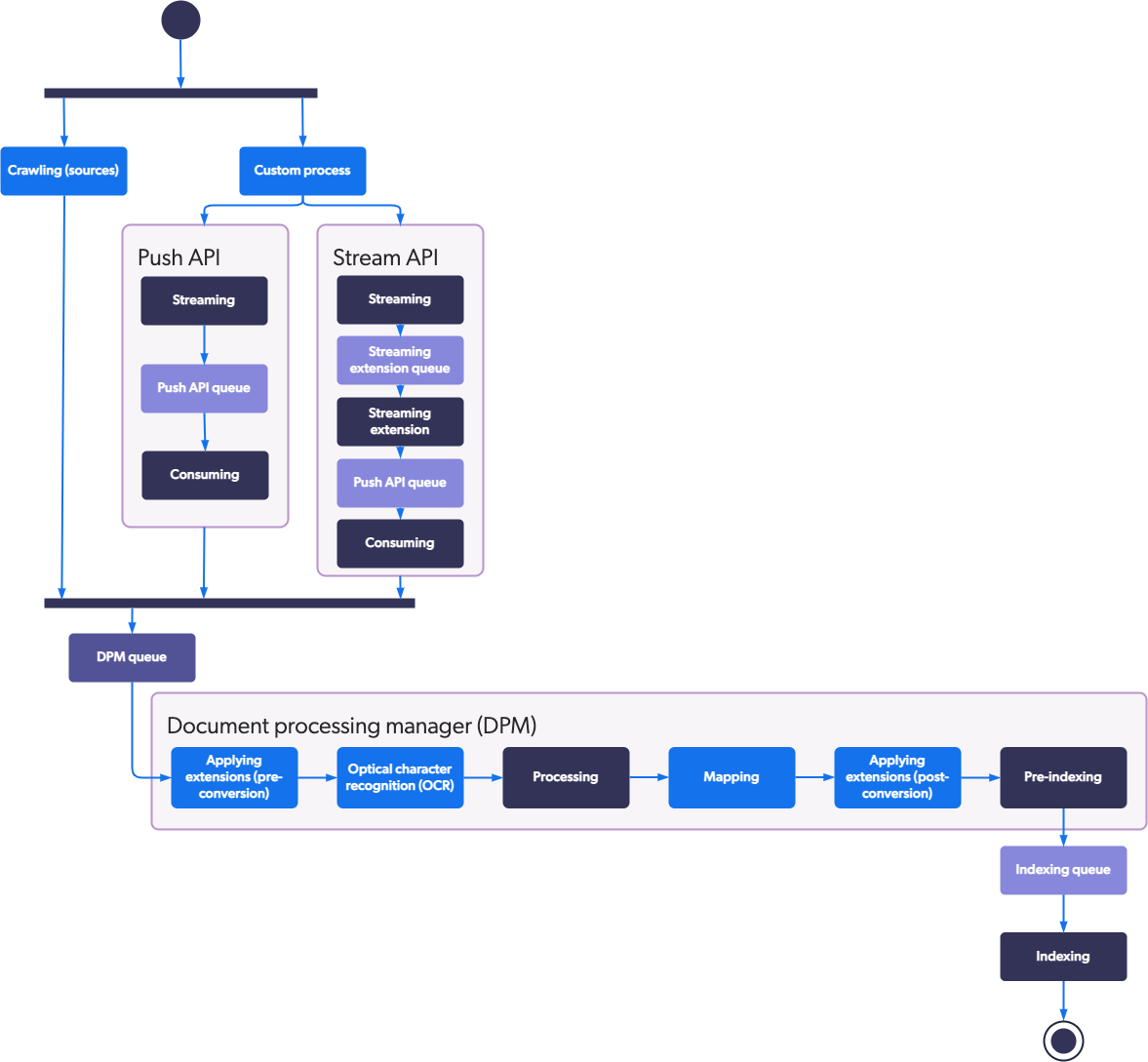
A distinction should be made between an indexing pipeline and a source of content, for clarity’s sake. A source of content (crawler or Push) is configured in the AdminUI to allow documents to be extracted from an external system. The extracted content is then sent into the indexing pipeline, but each source has its own rules about what should be performed on the document by the indexing pipeline. In short, we have one indexing pipeline that transforms the sources’ documents based on their configuration.
You use an indexing pipeline to prepare data for efficient retrieval during search. An indexing pipeline takes your raw data (documentation, help articles, etc.) and prepares it for indexing. At the processing stage of the indexing pipeline, candidate items are converted to a format suitable for indexing and automatic language detection occurs.
Part of the process is to convert various standard file formats. When the item is a PDF file, for example, the Coveo PDF converter extracts the text and the properties from the PDF binary file. When the item is an HTML file, the HTML converter extracts the text from the body element and metadata from the meta elements.
Overall, three steps typically comprise the indexing pipeline process.
Stages of the Indexing Pipeline:
- Preprocessing: Clean the data or generate a document body based on the available structured data. Think of multiple metadata to express someone’s address (street, city, state, etc.). Preprocessing can be executed to create a body that will represent the combination of all these pieces of information (textual aggregation).
- Transformation: Extract text and metadata from binary file format.
- Index building: Create an organized structure to store processed data and allow for efficient search.
Relevant Reading: Query Pipelines: How They Shape Search Experiences
Indexing Pipeline Best Practices
Keep these best practices in mind to make sure your indexing pipeline delivers the best result:
- Start with a single indexing pipeline (you can add more later).
- Use additional pipelines if you have a powerful system and a high volume of data, but don’t forget that running multiple indexing pipelines can strain resources.
- Keep a clean index for faster, more relevant search without having to maintain complex rules to filter out useless data. You can do this by, first, only indexing data and documents relevant for the index, and, second, by defining fields only for the queried data. By not indexing irrelevant information, you avoid slowing down indexing and query performance.
- Utilize appropriate data structures based on data types and expected queries.
- Continuously analyze search logs and user behavior to identify potential indexing gaps or areas for improvement.
What’s an Example of an Indexing Pipeline?
Let’s say you’re an ecommerce store selling athletic wear online. Here’s a possible indexing pipeline to use for your product data, so that visitors to your ecommerce site can easily find and purchase the products they’re looking for:
Stage 1: Data Extraction
Retrieve product data (product ID, name, description, category, brand, price, color, size, and stock availability) from a database or a product information management (PIM) system.
Stage 2: Data Cleaning and Preprocessing
Clean the extracted data by removing inconsistencies, typos, and empty fields. Standardize units (convert all prices to a specific currency, for example) and normalize data formats (e.g., make sure that a specific attribute, such as product color, is in lowercase).
Stage 3: Data Enrichment
Enrich the data with additional information to improve searchability. You could, for example, generate synonyms for product names (running shoes vs. sneakers), extract keywords from product descriptions (“casual basketball shoe”), and assign product categories based on a predefined taxonomy.
Stage 4: Text Analysis
Use advanced techniques like stemming (reducing words to their root form) or lemmatization (converting words to their base form). This will ensure that searches for plurals or different verb conjugations still find relevant products.
Stage 5: Build the Search Index
Take the processed data and build an inverted index, which is a data structure specifically designed for fast text retrieval. The index stores product information along with relevant keywords for efficient searching.
How to Add an Indexing Pipeline
You’ll put all info retrieved by a source into the Coveo indexing pipeline before it’s actually indexed. Items find their way into the indexing pipeline in two ways:
- Source crawlers
- Push API or Stream API
Typically, this process breaks down as follows:
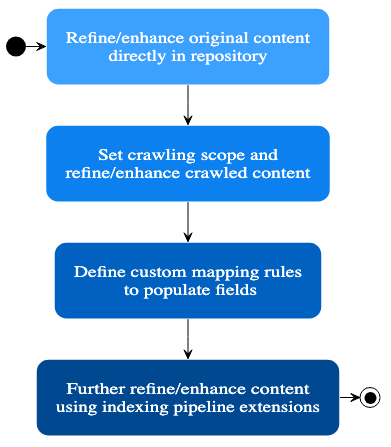
- Source Configuration: Defines how Coveo retrieves data from external sources. You can configure filtering rules to specify which content gets ingested and crawling schedules for data updates.
- Pipeline extensions: These are custom Python scripts that run during indexing and allow you to perform advanced data processing tasks. This offers the most flexibility for implementing custom indexing logic similar to a pipeline’s “transformation” stage.
- Mapping: Defines how the retrieved data gets transformed and mapped to Coveo’s internal search schema. Use mappings to extract specific information from the data source, clean or pre-process text data, and enrich the data with additional metadata. This is essentially the “post-processing” stage.
- Coveo Search Framework tasks (ongoing): Automatically performs various tasks during indexing, such as tokenization, stemming, and text normalization.
- Index options: Use language detection, text normalization rules, and weighting to further refine and optimize the indexing process for specific data sources and desired search behavior.
Pipeline extensions can be a powerful tool in your search toolbox. Using the athletic wear example above, you could use a pipeline extension to automatically identify and parse specific keywords that indicate color or sizing (“orange crew neck”, for example, or “size 12”).
The pipeline extension can then create new metadata fields within the search index specifically for these attributes, which allows users to filter their product searches more easily.
Relevant Reading: Manage Indexing Pipelines [Technical Docs]
How Does an Indexing Pipeline Improve Search Performance?
Configured properly, and in adherence to the indexing pipeline best practices described above, an indexing pipeline can improve search performance in the following ways:
- Reduce search time by pre-processing and organizing data in a structured way, so that the search engine can quickly locate the relevant information or content chunk.
- Quicken retrieval speed by pointing the search engine to the specific locations within the data where relevant information resides, eliminating the need to scan the entire dataset for every query string.
- Improve results ranking based on their relevance to the query by storing information like keywords, document summaries, and other factors used to assess how well a document matches the user’s intent.
- Enhance filtering and facetingso users can refine their search based on a specific parameter like date, author, or category, further improving the accuracy of the retrieved information.
- Handle a large dataset to scale search engines as the data volume continues to grow, ensuring consistent performance.
How Retrieval Augmented Generation (RAG) Enhances Indexing Pipelines
Fundamentally, indexing pipelines and a RAG pipeline are two separate tools used for different stages within information retrieval systems. But they can work together to enhance the overall user experience.
RAG builds upon the work of indexing pipelines. It takes a user’s query and searches the pre-processed data using the search engine. RAG retrieves relevant information based on the query and leverages this information to formulate a response.
Think of RAG as a knowledgeable librarian who, after consulting the catalog, uses their knowledge to point you to the most relevant books and provide additional insights.
Here’s an example:
Imagine an e-commerce website with an indexing pipeline for product data and a RAG system for answering customer questions. A customer types in the query:
“Best running shoes for flat feet?”
The indexing pipeline ensures product information is organized by features like shoe type and arch support. RAG utilizes the search engine to retrieve data on running shoes with good arch support and uses this information to generate a response recommending specific shoes suitable for flat feet. Additionally, RAG might incorporate user reviews or buying guides to provide a more comprehensive answer.
By using a well-organized and searchable data foundation created by the indexing pipeline, RAG can find relevant information faster and more accurately, while effectively avoiding hallucinations and security issues.
Relevant Reading: Retrieval Augmented Generation: What Is It and How Do Enterprises Benefit?
Search is for Who’s Searching. Indexing Pipeline is One Part of the Puzzle.
Building a search experience requires considerable resources and technical know-how. But let’s not forget who the search experience is for: end users that by and large have neither. By effectively using query pipelines and index pipelines, you can drastically improve this end-user experience, while tackling the common problems that people encounter when searching online.
For people searching for what to buy online, those problems remain true barriers to conversion. According to the Coveo 2024 CX Industry Report, search factors heavily among the most frequent problems that consumers encounter when buying online:
- Too many choices, difficult to filter or irrelevant filtering options (35%)
- Difficult to find what I wanted using search or browse (32%)
- No ability to select stock availability or availability by store (29%)
- Irrelevant product recommendations, not personalized to my preferences (25%)
- Chatbot product suggestions aren’t relevant (23%)
The purpose of a healthy, well-optimized indexing pipeline is to improve the search experience, first and foremost. Doing so opens the door to a number of downstream benefits, such as engagement, performance gains, and conversion rate.
Dig Deeper
Indexing pipelines are just one of many important parts of a search index to evaluate when selecting an AI search platform. Find what else to keep in mind in our free white paper, Buyer’s Guide for Best Enterprise Search Engine.