

Enterprise search seems simple, belying the complicated decisions involved with enterprise search engine replacement. You type a phrase into a box, press enter, then you get back a listing of all the things that you’re searching for.
If that was all there was to it, then search as a domain would likely end up being a quiet little backwater more or less lost in time, rather than one of the largest functions of the internet (and enterprises) today.
If you are responsible for enabling search in your company today, you probably realize that there is a whole lot of magic that takes place when you press the Enter key.
Understanding How Search Has Changed
To understand what you need so that you can migrate from an enterprise search solution like, say, Adobe’s Search and Promote, Oracle’s Endeca, or even an open source option like Apache Solr to a new search engine, it’s worth exploring how dramatically the technology has changed over the last 10-20 years since you committed to your last site search solution.
No search engine, whether hosted in the cloud or on-premises, actually reads through every single document in the corpus (i.e., the body of documents) when a search is initiated. This would be highly inefficient and time consuming, even with a relatively small number of documents. Instead, the vast number of search engines (whether on the web or for enterprise) work by creating an index when a document is first ingested.
As the number of webpages increased into the millions, simply returning a list of pages that contained specific keywords proved to be increasingly less useful. Using Boolean and/or multiple terms to pare down the results might get you to, say, 10,000 documents—far less than a million, admittedly, but still more than you could presumably get through in several days of reading.
This is one of the reasons that popularity and relevance became discriminating site search filters.
Popularity is a measure of how many people end up visiting a given webpage. This is fairly easy to calculate because most search engines maintain a rolling average of counts over a specific period of time. It also helps ensure that older content doesn’t simply overwhelm the ranking.
Relevance is, in many respects, more a goal than a measurement, and its definition varies. In AI-powered enterprise search, machine learning uses end-user behavior to ‘measure’ the relevancy of searched documents. ML models will also take the context of the end-user into consideration, such as the geo-location of the search request, the user’s language settings, and more.
While relevance is often reduced to a single number for computational purposes, it may be calculated based upon factors such as keyword similarity, topical overlap, logical inferences, and other kinds of basic semantic similarity.
What’s notable about relevance is that it describes a user or users’ relationship with documents. If you connect various documents together via their relevance as divined through user interaction, you effectively create a graph of relevant information. This is where enterprise search evolves into cognitive search and begins to leave the boundaries of the individual page and instead becomes more semantic in nature. Put another way, the metadata associated with both past searches users have conducted and the current in-session data become part of the computation determining the relevance of those documents.
Enterprise Search: More Than Just Documents
In the last decade, many site search innovations now found in the largest search engines are increasingly making their way into enterprise and even personal-level search engines. One of the first is a redefinition of what comprises a “document.”
In the early days of search, a document was a webpage—a block of HTML with links to CSS and Javascript. Later, as spidering engines became more sophisticated, this expanded to unstructured data like straight text, binary documents such as Microsoft Word and PDF documents, and then presentation files and spreadsheets.
Indexing Images and Video
Over time, images were also indexed by using channel histograms. In the last five years or so, image recognition systems and machine learning algorithms have advanced to the point where they identify specific shapes and patterns in images and video, indexing these to catalog them thematically rather than simply by color or file type.
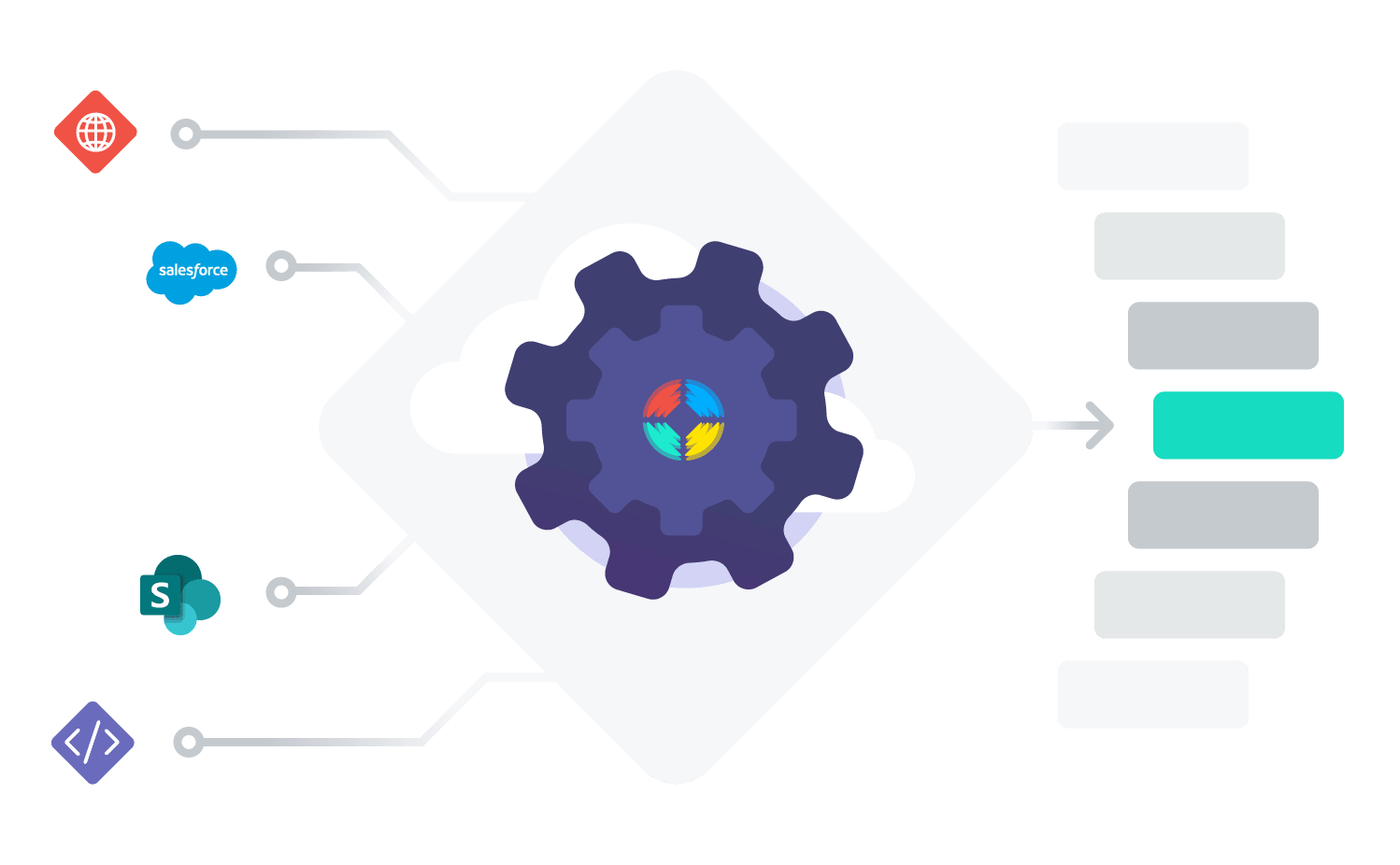
An AI-powered enterprise search platform like Coveo can use these types of third-party systems to enrich the indexed enterprise data.
Indexing Speech
Similarly, speech-to-text processing is able to create searchable transcripts that identify not only what was said, who said it, and whether there is any actionable intelligence that needs to be taken.
The pandemic has brought other changes, not least being the use of such systems to transcribe and index the content of video conferencing used in corporate communications. This includes the ability to not only find out what was said in a meeting last week (or last year), but to create both passive links to resources and hooks to perform actionable items.
Consider events such as automatically establishing the software infrastructure for a particular project or initiative. This could include project management tools and assignments, budgetary decisions, and the creation of smart contracts—a key move towards digitally transforming a company.
We’re not quite there yet, but these will all be emerging within the next one to two years as search systems become more and more sophisticated.
Indexing Data
Another area where site search is becoming more seminal is in the realm of data documents. The line between data and document has always been somewhat blurry, as even the most narrative of structures has a certain amount of metadata that identifies specific characteristics about all or some of a given story (publication dates, summaries, stylistic content and so forth) that usually requires some kind of framework structure (HTML or XML, typically).
However, two key things rose from the Semantic Web movement (only somewhat related to semantics in a search sense). First, you can create structured documents with property tags that can represent any entity (a person, a business, a vehicle, even an idea) and hold any kind of data (what’s frequently called a data model).
Second, by creating globally unique keys or identifiers for various resources, it becomes possible to retrieve that representation by telling a router what resource you’re looking for (using the identifier), and more recently even telling it how much of the data you want from various data sources. In other words, search increasingly allows you to retrieve any sort of document, even documents that are collections of data.
Query languages provide ways of retrieving a subset of a document set that satisfy the conditions of the query. Typically, when you type a phrase in a search box, the search engine for that site takes that phrase and transforms it into a query language request that is then used to retrieve a listing of enough of each document to help identify it, along with a link to where it is located (its uniform resource locator or URL, most often).
This two-stage process of querying to retrieve a relevant set then going from that site to an individual document is so intrinsic to the way that we work with the internet that we often don’t actually think about it as being a multistage process.
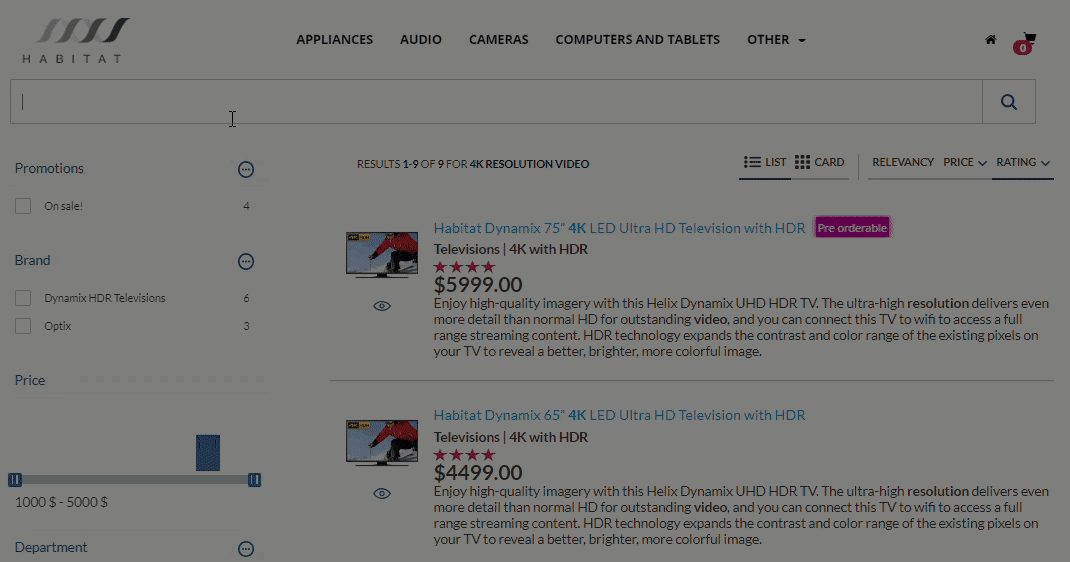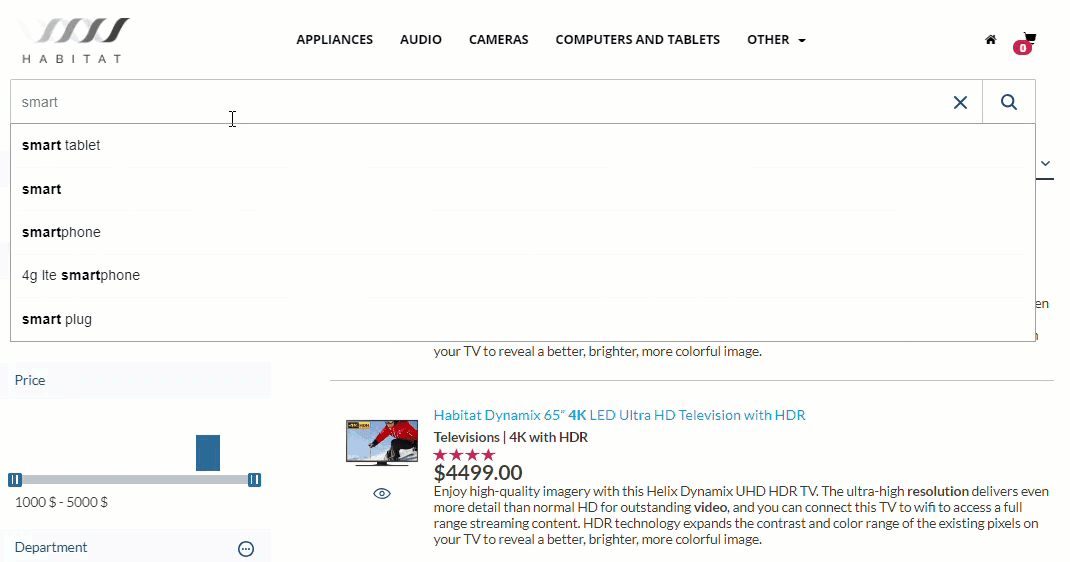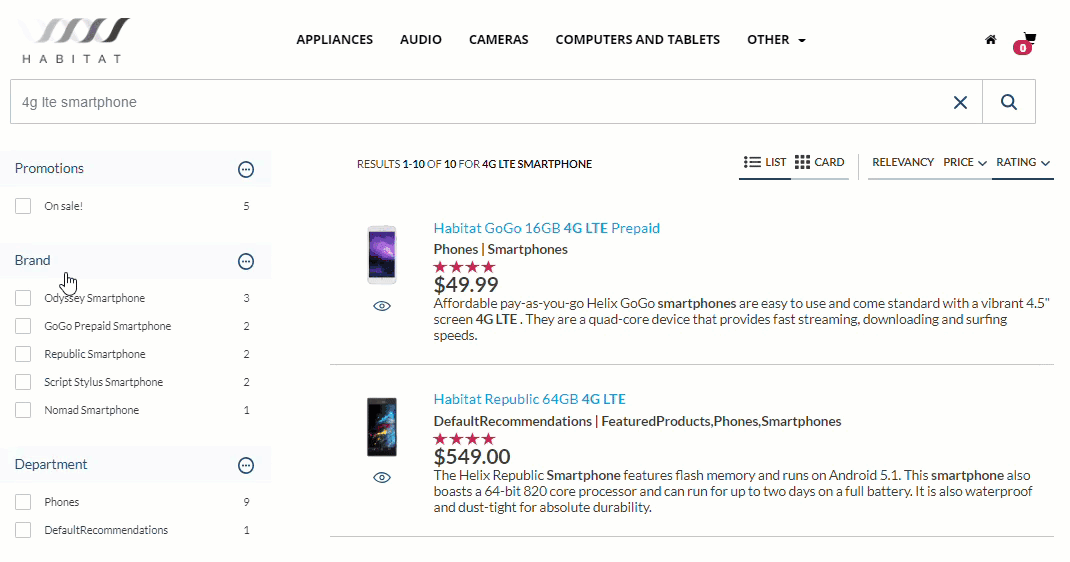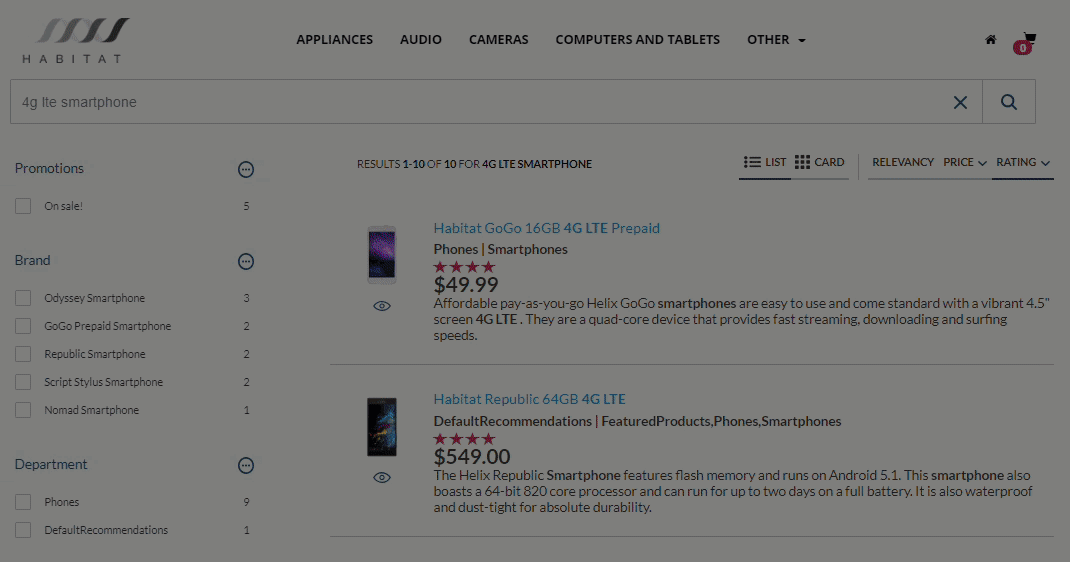
Indeed, query suggestions with type-ahead works in exactly the same way, save that instead of generating a new page, the query suggest uses the cues from the search text to populate a drop-down box, an item (or in some cases, items) of which can then be selected for retrieval.
Context and the Future of Enterprise Search
Relevance, as mentioned earlier, is a remarkably fluid concept, especially as it relies upon something that we tend to intuitively understand but find very difficult to define: the notion of context.
What is relevant to one person may be relevant to another—or it might not be. Context can be thought of as the metadata that a given person or organization brings to a search, and it changes over time.
For instance, a high school student writing a report on cancer will likely be looking for very general information about what a cancer is, what type of cancers there are, maybe how you detect and treat them. An oncologist, on the other hand, will know all of this and may be interested specifically in finding the availability and activation pathways of a certain cancer drug.
This is actually one of the areas where chatbots shine. A chatbot in general is a search agent, possibly with some speech to text capability, that additionally creates an index based upon both the identity of the user and the history of previous queries. Such chatbots systems may also use machine learning algorithms (a form of artificial intelligence), natural language processing, and Bayesian analysis to better identify the intent of the user.
What’s important here is that this intent in turn is used to fine tune the model that the chatbot keeps of the user and their interests. This means, for instance, that a user who’s worked with a chatbot can say something like “You know, last time you pulled up the chemical pathways for Anastrozole. Could you pull that list up and give me other drugs that might treat the same pathways?”
This kind of query has in the past been incredibly difficult to do, because it necessitates both retaining a history of prior transactions, then using that history to make inferences against different databases, without necessarily knowing what those databases are, then finally preparing that information in a format that is meaningful. It is this kind of query, specifically, that a search engine or platform like Coveo in particular is quite capable of doing.
The other side of this equation, the data access side, is also evolving. Increasingly what used to be called content management systems are becoming knowledge management systems (or knowledge-bases), in which data, documents and metadata are intertwined and fully accessible, and in many cases can readily morph from one to the other.
Knowledge-bases serve to hold the state of holistic systems and mark the next stage of evolution for the database. It is very likely that over the next decade, contextual search and knowledge bases will become even more tightly integrated.
What’s Next?
So given all this, where do you start when facing a replacement?
In part 2, I’ll look into how you can prepare for migration—and the steps you need to take to migrate successfully.
Dig Deeper
Wondering where to get started when looking to evaluate different enterprise search platform options on the market? Check out our Buyers Guide for Enterprise Search Platforms for the inside scoop.