







Gaining access to the right information quickly and reliably is fundamental in the success of today’s businesses. From employees in customer support looking for product information in document repositories to customers searching for top-rated products that match their requirements on a brand’s online shop, information retrieval touches nearly every aspect of our lives and the operation of businesses.
In this blog, we explore how far information retrieval (IR) has come from its early days to its modern form rooted in artificial intelligence, giving businesses a deeper understanding of where we were and where we’re headed.
Organizations will gain greater insights into how quickly AI is evolving in light of technological developments and ways they can use an advanced information retrieval system to address today’s challenges.
Early Methods of Information Retrieval
Information retrieval is the process of finding relevant information from a collection of documents. Humans have been creating systems to organize and retrieve information long before the digital age.
Card catalogs
Cataloging, which involves creating records and descriptions of the items in a collection to identify and access them, laid the foundation for today’s information retrieval systems by giving structure and findability to data.
In ancient Greek times, the Library of Alexandria used an early form of card catalogs that allowed scholars to search the scrolls and find important works of the day in this prominent center of learning and knowledge.

Around 250 B.C., Greek poet and scholar Callimachus produced for the Library of Alexandria what many consider to be the first library catalog. Called the “Pinakes,” this catalog consisted of an alphabetical listing of authors and their works separated by subject, with data such as the opening lines of the scroll, setting the foundation for modern card catalogs.
The Dewey Decimal System
In the late 19th century, a formal system of organization emerged with the introduction of the Dewey Decimal System, the widely adopted cataloging and indexing system foundational to modern library classification.
Published in 1876 by librarian Melvil Dewey, the numerical system classified books in a hierarchy relative to each other by topic. It divided knowledge into 10 main categories, each with 100 subcategories. At the time, each library’s system was unique, assigning a placement of a book on the shelf upon entering the collection based on factors such as book height and the date it came to the library.
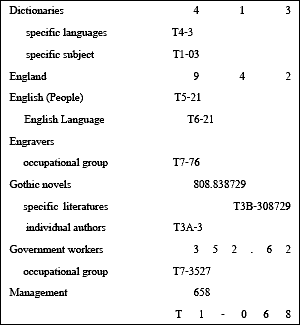
The Dewey Decimal System standardized and revolutionized the way libraries organized their collections, making materials accessible to any library visitor, no matter their familiarity with the collection.
It introduced a systematic approach to organizing information by its relation to other information, which modern IR systems also use to represent relationships between concepts, making it easier to retrieve information from large datasets.
The Dewey Decimal System and card catalogs brought order to the print era, yet new methods for information retrieval were necessary with the explosion of information introduced by the digital age.
Advent of Digital Information Retrieval
A shift from physical to digital information retrieval emerged with the introduction of computers in the mid-20th century. The first instances of computer-based searching systems appeared in the 1940s with information retrieval capabilities growing alongside advances in processor speed and storage.
The term “information retrieval” was coined in 1950 in a paper presented by computer scientist Calvin Mooers. During this period, information retrieval evolved from manual indexing and searching for information to automated systems.
In the 1960s, IBM created STAIRS, one of the first large-scale general-purpose information retrieval systems for managing large text-based datasets that was influential in developing commercial applications of IR, such as in enterprise systems.
Gerard Salton at Cornell University developed the System for the Mechanical Analysis and Retrieval of Text (SMART), becoming an early pioneer of the concepts that are instrumental to today’s search engines such as vector space models for text retrieval and term weighting in ranking relevance.
Rise of the Internet and Search Engines
With the 1990s came the advent of the World Wide Web and early search engines. The internet connected information and people like never before and suddenly opened up access to a flood of data.
At the same time, people adopted personal computers for both home and workplace use. As use of the internet and ecommerce grew, people needed a way to navigate newly created web pages and retrieve information they wanted, and web search engines were born.
The earliest search engines, such as Archie and Gopher, actually predated the World Wide Web and allowed users to find files stored on FTP servers through simple text-based searches of file names.
In 1991, the World Wide Web went public, leading to an explosion in information accessible to everyone and the need for systems that could handle more complex searches.
Keyword-based search engines emerged. Yahoo! Search was one of the first popular web search engines, making it possible for users to search the Yahoo! Directory, although its capabilities were limited to this directory.
In 1996 while at Stanford University, Larry Page and Sergey Brin, co-founders of Google, first developed PageRank, the web page ranking algorithm used by the search engine. PageRank changed the internet’s information retrieval landscape by ranking web pages based on relevance and authority.
Unlike traditional keyword-based ranking systems, PageRank ranked web pages based on the quality and quantity of links pointing to the page. Google’s dominance grew thanks to its superior relevance-based algorithm.
Today, while PageRank remains foundational, Google continues to refine its search algorithms.
Era of Big Data and Machine Learning
In the early 21st century, the volume of data surged due to web traffic and online stores. This era introduced Big Data and saw a dramatic rise in structured and unstructured data from sources such as social media and smartphones.
Big data refers to data sets that are so large and complex, they are challenging to manage through traditional methods or tools. As the data landscape grew, keyword-based searches proved inadequate for accurately retrieving information from this massive pool. This gap highlighted the need for AI-driven systems capable of handling and querying Big Data more effectively.
Unlike simple keyword-based searches, AI-based information retrieval systems use techniques such as machine learning and natural language processing (NLP) to understand user intent, context and the nuances found in semantics to provide more relevant and accurate results.
Machine learning is a subset of AI that trains computers to learn from data and improve over time. NLP, another subset of AI, uses machine learning and deep learning to interpret and replicate human language.
Their integration into information retrieval systems significantly advanced the field by enabling quick data analysis and a deeper understanding of query context and semantics.
Current Trends and Innovations
Information retrieval has rapidly evolved beyond simple keyword matching toward context-aware systems that improve accuracy, relevance, and user interaction.
Today’s AI-driven information retrieval systems integrate machine learning and natural language processing, along with advancements in deep learning, to understand user queries in context and take into account the subtleties in language, or semantics, when matching the queries to documents.
These systems bring contextual understanding to information retrieval, analyzing relationships between words to understand semantics in user queries and documents (e.g., the different meanings of “date”) which makes search results more accurate. They are also able to consider factors such as search history and user profiles to personalize results to match each user.
AI-powered algorithms like Google’s BERT and RankBrain exemplify this trend by analyzing user queries and delivering more relevant results. By incorporating natural language, AI search has also evolved toward human-like, or conversational, interactions. OpenAI’s GPT, a large language model trained on vast amounts of text data, generates contextually aware text to answer user queries in a human-like manner.
In enterprises, AI-driven information retrieval has surpassed traditional systems in managing the complexities of today’s data-rich organizations. AI-powered search now allows enterprises to quickly locate crucial documents across vast repositories, creating smoother knowledge sharing and quicker customer service. AI has also allowed companies to provide personalized recommendations, increasing satisfaction among users whether they are employees or customers.
Future of Information Retrieval
There are many emerging trends and innovations in information retrieval worth exploring, as covered below.
AI advancements
Further developments in AI, natural language processing and deep learning will likely shape the future of information retrieval. For example, the next generation search engine using large language models may use conversational question-and-answer techniques to better capture user intent and deliver faster results.
Voice search
Search will continue to become more conversational with voice-enabled search. A generation of kids is growing up with voice search enabled devices such as Siri and Alexa. Weekly voice searches are a habit of 1 in 5 people. Voice search is already integrated into AI-driven search engines ChatGPT and Google’s Gemini. Combined with NLP to interpret complex queries, voice search may lead to longer, more conversational queries, creating new opportunities for businesses to optimize content and websites accordingly.
Augmented reality
Through augmented reality, what we know today as visual search will become more mainstream, increasingly blending with superimposing visuals in the world around us. Google already offers 3D images of results in Google Search through a phone. Companies currently offer tools that use augmented reality to visualize furniture placements or test shades of lipstick. Augmented reality search could extend this by enabling users to visualize and purchase products directly from their surroundings. In enterprise applications, augmented reality could soon empower employees to access information about people, equipment, or buildings using a pair of smart glasses.
Quantum computing
With the advent of quantum computing, information retrieval stands to benefit from the ability to handle vast amounts of data and process that data at unprecedented speeds. Quantum computing holds the potential to revolutionize IR with exponential increases in the speed of data retrieval, enhanced pattern recognition, and more efficient search algorithms. In turn, these advances promise accuracy and efficiency that today’s computers simply cannot match.
Coveo’s Contribution and Solutions
Coveo has emerged as a leader in AI-powered information retrieval.
At Coveo, we know that AI-powered search capabilities are key to enterprises overcoming challenges in information retrieval, whether that’s improving customer self-service with generative AI to increase customer satisfaction or increasing the speed and accuracy with which employees search for knowledge and documents.
The Coveo Platform™ provides enterprises with search and analytics solutions for generative answering, semantic search, AI recommendations and automated personalization.
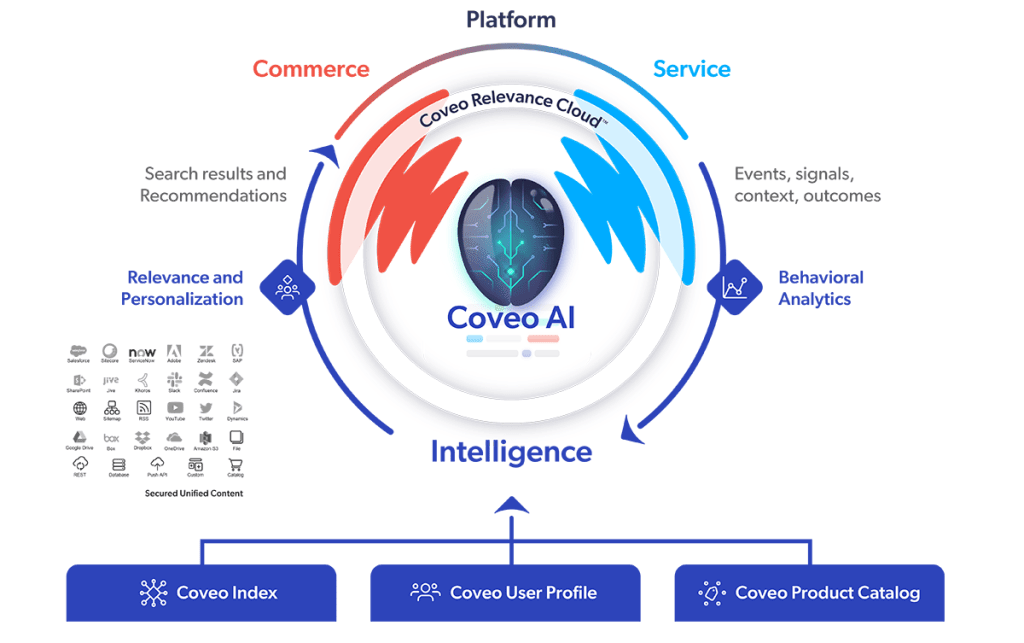
MAC Cosmetics transformed its ecommerce experience with Coveo’s AI capabilities, using past customer behavior to suggest relevant products, like a previously purchased lipstick shade.
Deploying AI-enhanced search with features such as generative answering, Coveo customer F5 Networks was able to provide customers and support agents with self-service resolution and unified access to knowledge articles across the enterprise.
Conclusion
Information retrieval systems have advanced rapidly from ancient libraries to our modern times, driven by breakthroughs in AI and deep learning. With the continuous accumulation of data from a growing number of sources, new challenges will emerge along with exciting solutions for information retrieval and search. Information retrieval systems are positioned to remain pivotal in helping us interpret the great volumes of data around us, and organizations that stay updated on retrieval trends will be better equipped to access information accurately and efficiently.
Enterprises can stay ahead of the curve by exploring advanced information retrieval systems for their businesses.
Engage with Coveo for cutting-edge information retrieval solutions.