
Do you find your data cleaning best practices lacking? As the saying goes: Garbage in, garbage out.
A great search experience often hinges on the quality of content and data that the search system delivers to users.
Offering a search experience based on outdated, missing or inaccurate data can sour your customers’ shopping experiences or eat into employee proficiency. Nobody wants a potential customer to land on the dreaded no search results page, nor have employees waste time sifting through mislabeled documents. Ever wondered what bad data is costing you? According to Gartner, an average of $12.9 million annually.
Despite data’s critical importance — especially since it informs business leaders’ decisions 16 times per day on average — data hygiene issues persist. A whopping 95% of the 1,000 participants in a global study across industries by Experian felt that poor data quality undermines business performance.
So how do businesses overcome the data quality problem? We believe the solution starts with the fundamentals of good data management, a core tenet of which is data cleaning. Let’s walk through what leads to poor quality data, what’s involved in data cleaning, and best practices for maintaining clean data so your business is prepared to make data work for you instead of against you.
What Is Data Cleaning?
The term data cleaning, sometimes referred to as data cleansing or data scrubbing, refers to the process of finding and correcting data that is inaccurate, inconsistent, duplicate or outdated. The goal is to ensure that high quality business data is available at any given time. Data cleaning is an essential step in data preparation before indexing or analysis.
Cleaning data usually involves addressing errors such as duplicate values, wrong syntax and spelling, outdated information, and missing data. Standardization is one important way to clean data, meaning changing differing data formats into a common one that’s applied across data sets. While software such as data auditing and data validation services are available to help, much of data cleaning must still be accomplished manually.
Data cleaning is time consuming and has been performed traditionally by data quality managers and engineers. But in today’s data-driven business environment, data hygiene affects everyone in an organization. Increasingly the responsibility for maintaining data quality is widening to include the business users and data stewards from business units in a distributed model of data ownership.
The Importance of Clean Data
You need clean data before you can use and analyze data for your business purposes, especially if it’s going to be fed through a machine learning algorithm. But without a data cleaning practice in place, companies run analyses and make the wrong conclusions based on bad data — and the consequences are far-reaching.
The financial toll, for example, can be huge. IBM estimates an annual cost of $3.1 trillion in the U.S. due to poor data quality. Poor data costs businesses in wasted man hours, ineffective marketing campaigns, loss of business from poor customer experiences, and delays in moving forward on strategic business initiatives. Errors in data also lead to customer dissatisfaction, employee frustrations, and wrong data insights, to name a few more.
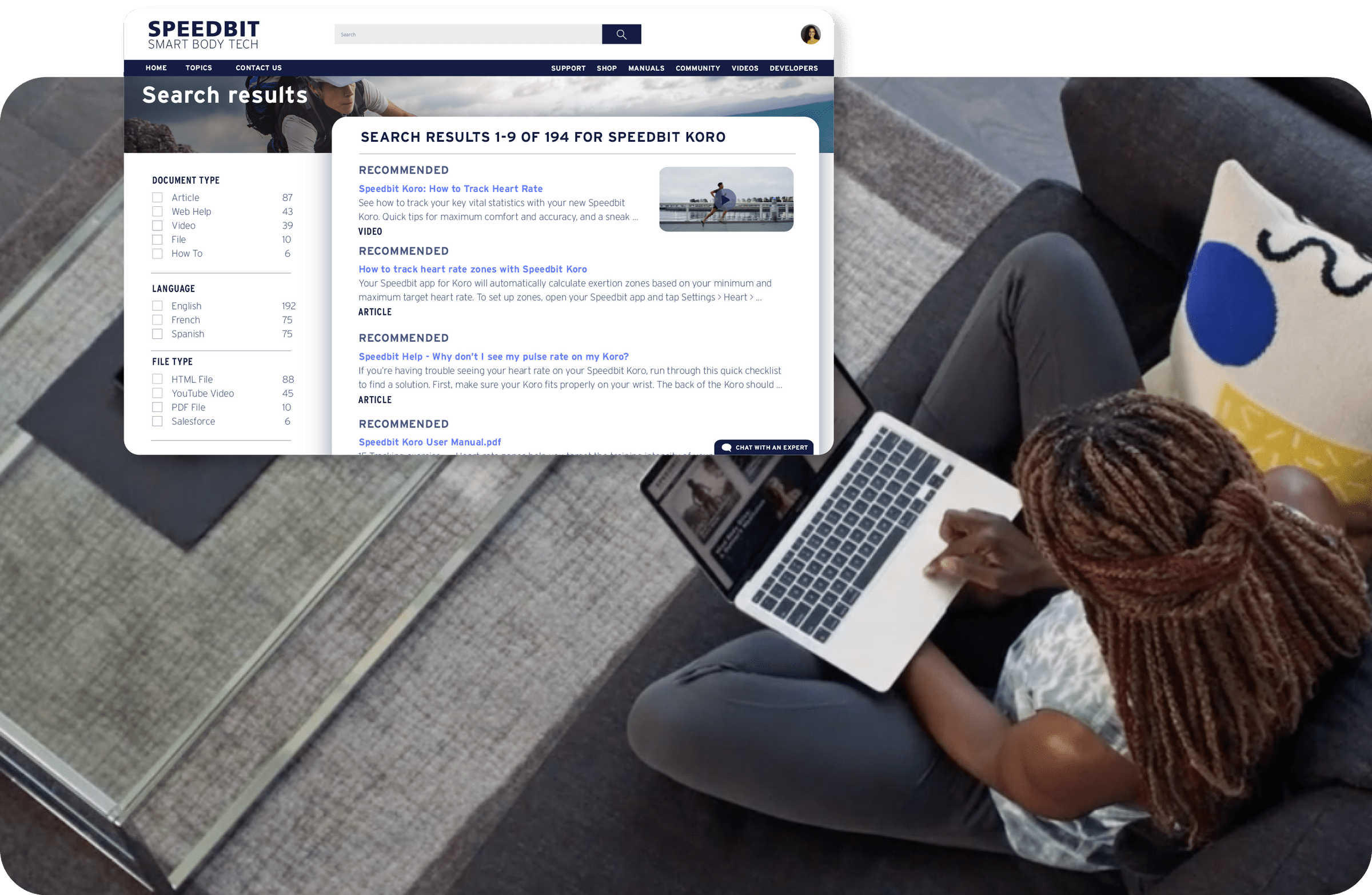
The Consequences of Messy Data in Search
In search, inaccurate data — such as in metadata assigned to assets — causes all kinds of problems, like making it impossible to properly index a file. This creates frustrating search experiences for your customers or employees, which in turn harms your brand or company culture.
On the flip side, good data equips companies with an accurate understanding of their customers. This empowers them to create highly personalized and relevant experiences. In a time when a company’s competitiveness for consumers’ wallets depends on providing excellent, individualized customer experiences, data can play a pivotal role in a company’s ability to deliver those experiences.
But the success of these efforts depends on maintaining those repositories of high quality, reliable data.
What Causes Dirty Data?
Data can be considered bad quality or “dirty” for a variety of reasons. Some of these include:
- Incomplete data, like missing contact fields (e.g., phone numbers, addresses, emails)
- Outdated information
- Duplicate records in your data set
- A missing value
- Data error like spelling mistakes or inconsistencies
No company is immune from the dangers of dirty data. With the volume of data growing exponentially today and flowing in from multiple sources and systems, the potential for errors in data is high. A third of poor data is due to human error, but dirty data also results from merging data sets from disparate systems containing conflicting or duplicate data.
Another culprit is the fact that data deteriorates rapidly in its accuracy and relevance. If you’re looking to reach a B2B prospect, according to ERP Advisors Group, remember that 30% of people change their jobs every year, leaving your contact data obsolete. And in B2C, within a year 43% of consumers change their phone numbers and 25 to 33% of email addresses become outdated.
Clean data is data that’s correct, consistent, complete, and uniform across different data sets.
What Makes Manual Data Cleaning So Challenging?
Manual data cleaning is challenging due to the time-consuming nature of handling large datasets, the need for specialized skills to identify and rectify inconsistencies, and the potential for human error. This can delay projects and reduce productivity, impacting ROI and efficiency across the enterprise.
Using tools like indexing pipeline extensions and artificial intelligence to automate the process can help to massively simplify an otherwise difficult process.
Why Data Cleaning Matters for Search
Search emerged even more prominently following 2020 as an essential part of our shopping experiences and work lives. As social distancing forced more people to ecommerce and remote work, search has been central to getting us to the products and information we need.
In any information retrieval situation, ensuring you have clean data and content before indexing is crucial to align metadata for the best end user search experience. Clean and standardized data ensures a search engine can find all related content easily, which is key to presenting the most relevant search results.
The indexing step in setting up search allows us to fetch and store content in a structured manner. It’s important to store all customer data collection in a standardized way so the right information can be retrieved. (For example, “tennis shoes” vs. “shoes for tennis” variants can lead to “tennis shoes” ranking higher even though they describe the same thing.)
In this context, data cleaning mainly consists of efforts to:
Remove obsolete data and irrelevant observations
For example, if you fail to remove old emails from your CRM, this impacts the effectiveness and productivity of a sales outreach campaign to existing customers.
Correct bad metadata
In terms of metadata, you might have a metric called “dimension” in your product catalog that contains the values “1 m,” “1m” and “1 meter” where there should be only one standard value. This prevents your search engine from presenting certain products to consumers, leading to losses in sales and revenue.
Let’s look a little closer at how the cleanliness of your data can affect common search use cases.
Product Catalogs Search
An online product catalog is both the online storefront for your customers as well as a source of valuable information about your customers. Standardizing this information leads to making it easier for your customers to find what they’re looking for and easier for you to analyze their behavior, such as understanding why they abandon their carts.
Clean and standardized data allows for storing information in a meaningful way in your product catalogs and displaying the values to customers in a consistent way.
Documents Search
Clean data is also important to the document search experience, whether for potential customers looking for resources on your site or employees seeking certain internal files.
If metadata belonging to documents is inconsistent, such as the spelling of an author’s name (e.g., “Henderson” vs. “Hendersen”), the searcher’s digital experience will suffer.
In a remote work situation, employees searching for a certain HR document when only older files have been indexed will have a hard time. They’ll likely only come up with out-of-date procedures. This could result in employees making decisions based on obsolete information.
Why A Data Cleaning Process Matters for Machine Learning
With the enormous volume of data generated today and high consumer expectations for personalized experiences, more companies are turning to machine learning and artificial intelligence to help deliver those experiences at scale in a way humans alone cannot. Machine learning can help bring the most relevant query results, for example, across all of your customer or business user searches by learning from both aggregate and individual user data.
Put simply, clean and structured data equals better machine learning performance. Training a model based on dirty data means the machine learning model will produce inaccurate predictions.
Other Consequences of Dirty Data on Machine Learning
Poor data quality hinders businesses from using more advanced technologies, according to a survey by PricewaterhouseCoopers, with 76% of companies planning to gain value from using AI, but only 15% saying they have access to the right data to reach that goal.
Clean data in your product catalog can enhance search experiences driven by machine learning. It creates stronger and more accurate relationships between your products and customer needs, which leads to more relevant product recommendations.
Coveo machine learning models require that fields are mapped and standardized properly. When clean data is not maintained, a machine learning-powered search can start suggesting the wrong content or fail to find the right content due to improper mapping. Machine learning can only learn from and act on the data it’s fed, messy data will lead to irrelevant results no matter how strong your machine learning algorithm or search software.
Relevant Reading: Mapping Metadata: Tips for Best Search Results
8 Business Benefits of Data Cleanup
We’ve touched on the advantages of data cleaning but let’s take a closer look at the benefits of maintaining clean data.
Data touches nearly every aspect of business and operational processes. When there is an organization-wide recognition of the importance of data cleaning, the upsides are many and include:
Better, more consistent search experiences
We examined this above, but put succinctly, high quality data sets you up for delivering high quality search experiences.
Good business decisions based on accurate content
Many business leaders today rely heavily on data for their decision making. That data must be clean to lead to the right decisions and better business outcomes.
Increases productivity
Without the time-consuming efforts of correcting inaccuracies in data or finding missing information, employees have more time to dedicate to high-impact tasks.
Streamlines processes
With clean data, the downstream processes that depend on high quality data will run more smoothly and efficiently without the need to clean up errors such as duplicates.
Ability to maximize the impact of machine learning
Clean data means better machine learning models to bring increasingly personalized experiences to your customers at scale. If you have bad data, you’re not allowing your investment in machine learning to reach its full potential.
Accurate predictions
Since we have clean and reliable data, we can accurately predict in a more precise way.
Enhances the results from analytics
When analytics reporting is in place, you must be able to trust reports. Clean data allows for reporting on the true impact of different features and builds trust needed to start taking action on insights.
Increases trust in data
A survey from Experian of 1,000 companies around the globe found that companies believed about one-third of their data was inaccurate. Consistently high quality data is key to turning this view around across an organization.
6 Data Cleansing Process Best Practices
Nobody wants dirty data, but maintaining clean data in a time of ever-growing data volume and complexity is quite challenging.
Let’s look at some general best practices for ways to help you keep your data clean:
Identify business use cases for improving data quality
Choose which areas of your business will benefit the most from higher data quality. Making clear connections between data assets and business outcomes can be used as a guide to form a database hygiene practice. For example, you may find your online store has become overridden with obsolete product information and you only sell 40% of the products stored in your database. You could come to an estimate of how much your data cleaning efforts will improve your store’s performance.
Standardize data entry
Decide how data should be entered and formatted into systems so that these standards can be followed across the organization. For example, inputting CRM data should include a standard way to enter a contact’s title and phone number (e.g., dashes or no dashes) or accepted abbreviations to describe industries.
Correct data at the source
Ensuring data is accurate at the source can save businesses many hours of labor and effort spent on correcting the data once it’s made its way into other systems and downstream processes. You can also improve data quality by checking if the data is correct upon entry.
Start with proper data procedures
When adding a system into your technology stack, implement data hygiene practices from the start. Set document categories and establish smart data policies. For example, limiting how many people can edit data or perform a duplicate check. Where possible, make dropdown boxes available to increase the chances of consistency in data from the start.
Set regular data cleaning maintenance
Data cleaning isn’t a one-time thing. It needs to be baked into your normal operational processes and data management.
Create a feedback loop
You may be using search software such as Coveo with an interface that shows discrepancies in your data. Pinpoint the source of dirty data and fix it. Then create a feedback loop by re-indexing content. Use the same interface to verify that the bad data is gone.

Bonus: Coveo’s 4 Data Cleaning Best Practices for Search
When implementing search software, clean data is a necessary first step. Here are best practices we’ve found helpful for maintaining clean data to deliver high quality search experiences. They include:
- Ensure that you’re tracking all relevant events in the proper way.
- Make sure you set the proper filters for the target of the indexing.
- Check your data after indexing to make sure it doesn’t contain discrepancies or missing values.
- Check for any metadata that is presented wrongly.
Data Cleaning and Coveo
Strong data preparation and cleaning are important steps to set proper indexing boundaries. And this is, of course, implementing intelligent search technologies such as Coveo. Additionally, Coveo helps provide insight into your indexed data. Through a review interface, Coveo showcases metadata discrepancies so you know where to focus your data cleaning efforts. A data validation feature in the platform also helps customers onboard with the right data tracking in place.
High-quality data gives your business a step-up over your competition. Committing to a regular data cleaning practice will produce the good data that is key to creating amazing digital experiences.
Dig Deeper
Data cleaning can seem daunting, but our ebook highlights why it’s the overlooked driver of better search experiences and company success. We broke it down to the 6 best practices.
Offering your customers the most relevant results to boost engagement and retention begins with serving them better information – the data you feed your LLM. Check out the ebook and move towards providing better search experiences.