

As you look to improve your personalization initiatives, it’s important to keep in mind two variables that impact shoppers: Shopper Intent and Search Engine Indexing. One might sound vague—while the other sounds pedantic.
We’ll show you how the two work in tandem—and why your search engine technology has to be up to the feat.
Importance of Determining Intent
Imagine entering a store looking for a pair of shoes. An attentive salesperson sees you browsing the women’s section and offers help. He asks a few pointed questions to help you narrow down your choices: do you want casual or formal? Do you tend to walk a lot? Do you want all-purpose shoes or a pair to fit a particular outfit? With his help, you figure out that you want a pair of low-heel closed black or brown all-purpose comfortable shoes in size seven.
He says that he has a few pairs in mind and retreats to look for them. He reappears 10 minutes later carrying only one pair and explaining apologetically that he also needs to run across the street to check the store’s secondary storage area.
Here’s the point where all the goodwill he earned for being attentive goes sour. Because even though he helped you figure out what you need, he wasn’t efficient at helping you locate that product because the store’s storage area is so poorly organized.
Intent Without Inventory … Equals Disappointment
On the other hand, we’ve all had the experience of going into a store and not being offered the help we needed. Maybe you came in looking for formal shoes and were simply directed to “aisle seven.” Or maybe the salesperson brought out all 25 pairs of formal shoes they had in your size. While a store’s merchandise might be perfectly organized and offer everything you need, it’s not helpful if you’re not being listened to.
These two examples illustrate two essential ingredients of a successful shopping experience in a physical store:
- An attentive salesperson who can decipher the customers’ needs and wishes without them having to spell out each one.
- A well-organized storage system where anything can be found easily.
The two parts complement each other. If one is lacking, the whole experience is a failure.
As ecommerce rapidly replaces physical shopping experiences, we realize that these ingredients are just as (if not more) important in the digital arena where we shop without interacting with salespeople.
In ecommerce, the equivalent of a well-organized storage system is a well-structured index, while the equivalent of an attentive salesperson is an AI-powered platform with advanced enough NLP capabilities designed to figure out the intent of the user as quickly as possible. In Coveo, the two components work together to provide users with the most relevant results as quickly as possible.
Importance of a Unified Search Index
Unlike a physical store, an ecommerce store has space for more than hundreds if not thousands of shoe styles. In turn, they each can come in a dozen sizes and maybe a dozen colors. This is an advantage as well as a challenge, because if this multitude of data points isn’t organized well, nobody will be able to find anything.
Additionally, they will have associated product descriptions, images, maybe video, and possibly customer reviews, and of course pricing—and whether or not it is in stock.
All this disparate data lives in multiple disparate systems. The goal then is to structure your search engine index seamlessly across these multiple data silos so that neither you nor your users need to worry about which data source the relevant catalog content is coming from. To do that, Coveo relies on unified search as opposed to the more traditional yet much less flexible federated search.
Unified Search vs Federated Search
When grappling with searching across data silos, the typical solution has been to send a single query to each database and present that information in their respective buckets.
While federated search is definitely a step forward from having to log into each separate system and search each data silo separately, it has its limitations when it comes to delivering relevance to the customer.
Specifically, because it delivers lists of results based on their content source, the results may be ranked by source but cannot be ranked by relevance across data sources.
In other words, today, federated search is simply not enough for most organizations’ UX needs.
Unified search differs from federated search in that it creates a single unified index of content from across all data sources—including the option to crawl or push content stored in the cloud or on-prem via connector library or APIs—and ranks all content while applying relevance across the entire corpus so that a user is delivered meaningful results, in a single interface.
In addition, unified search has faster query response times than federated search. This is because results are sourced from one unified index as opposed to searching multiple systems with query-time merging. By contrast, in federated search, the response times are only as fast as its slowest content source.
Structure of a Unified Search Index
One of the biggest advantages of unified search from a UX perspective is that your users don’t get distracted by the data source: they don’t need this info. But of course even when unifying search, you as the website owner will still want to know the provenance of your data-which source did it come from? That means your unified search index needs to be structured in such a way as to to maintain and easily access that knowledge.
Let’s imagine your ecommerce system consists of Customer Community, Customer Knowledge Base, and your Commerce Product Catalog. Thanks to unified search, the system displays within a single experience the list of products for purchase (powered by the Commerce Product Catalog source), and within that product list there are internal links to recent customer reviews (powered by the Customer Community source), and Helpful Advice and FAQs (powered by the Knowledge Base source).
Including all applicable fields and metadata in a unified index requires an understanding of the various data structures—along with how those sources and associated metadata will be used across various business solutions.
For example, Customer Community software was originally developed to simplify interactions between customers as they discuss the products offered by a company—as well as to enhance products by having customers provide feedback and ideas for additional features.
It purposely differs from a Commerce Product Catalog, which must have more granular detail (for example, Family, Product, SubProduct, Model, Version, etc.). Now complicate that with the Knowledge Base source which may have FAQ and Helpful Advice records that support multiple Models and Versions under a certain Family. A well-structured index will take into account the fact that the only fields relevant to the shopper would be Family A and Product X.
But how does a well-structured index do this, especially when areas like data field naming conventions can vary across data sources?
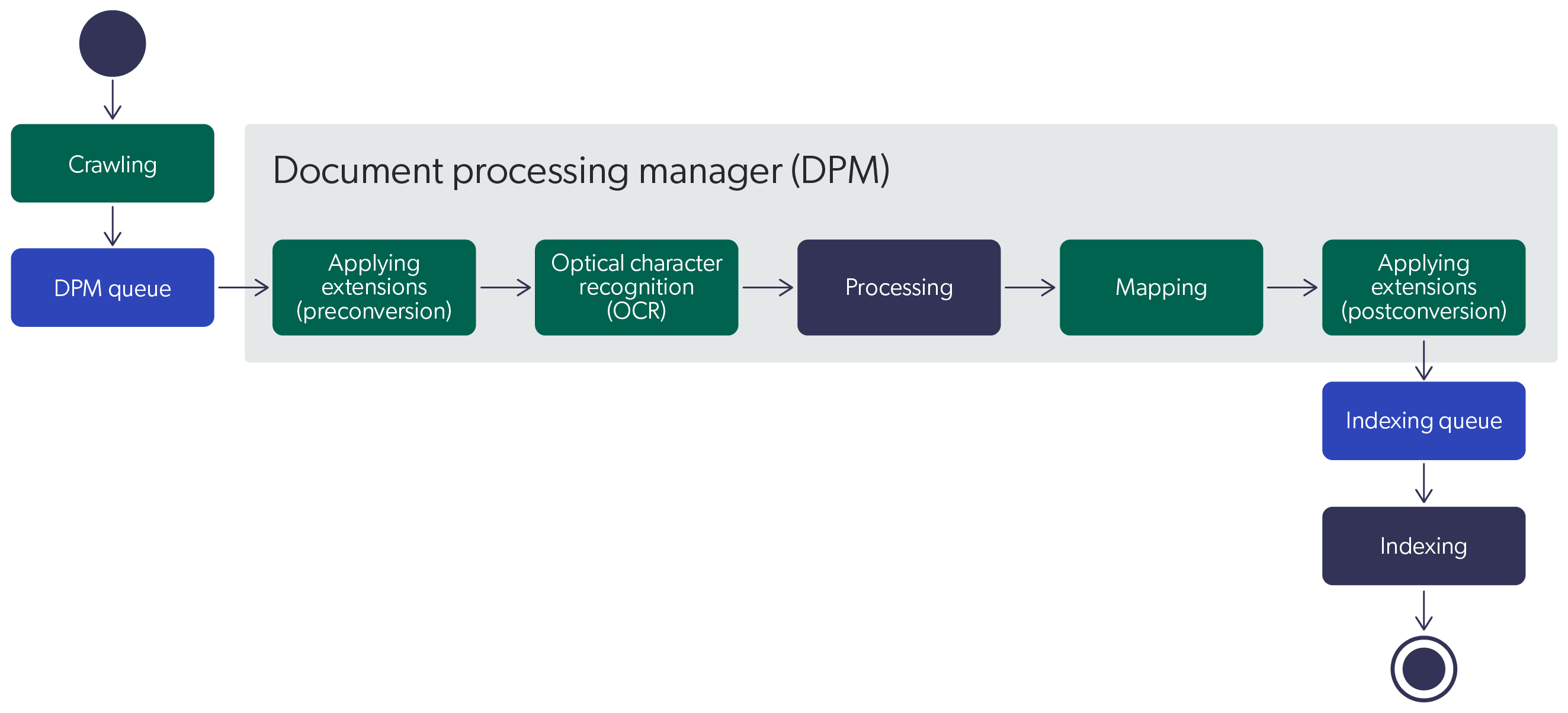
A Better Way to Align Data Sources
An old maxim is that when data is inconvenient, toss it; or in this case, flatten or isolate it.
To align data across various databases, we use what’s called “data flattening.” For example, to align data between Product Catalog, Community, and Knowledge Base sources, we could take the above-named five levels of the Product Catalog (Family, Product, SubProduct, Model, Version) along with the fields and metadata for the Community and Knowledge Base sources that would not normally have these levels, and add the field and associated metadata during indexing.
There is another consideration, too. Not all of the indexed metadata needs to be “free text searchable”—and a well-structured index will optimize how the various index fields will be used. For example, we might want to avail search on the Knowledge Base FAQ as well as Community reviews—but not on the Product Catalog’s multiple version numbers. Think of it as some fields that can be configured to support end-user search engine queries and power the business solutions’ UX (for example, facets, filters, templates, etc.). In turn, other fields can be used to enhance the relevancy AI models—while still others are used for reporting and data analytics.
The end user does not need to understand or care how the index is constructed. But an optimized unified search index will support multiple business solutions on the same index. Some business solutions (such as displaying a Customer FAQ document served up as a smart snippet by a Coveo-powered AI model when a user searches how to return a product) will leverage a small subset of indexed data to respond to simple queries. Other business solutions, such as ecommerce, leverage a high volume of indexed textual information that spans multiple solutions to respond to complex queries that are expected to change over time.
Business Logic Relevancy
Not everything can wait for source system structure changes—nor for end-user code to be updated. Imagine acquiring another product line and wishing to display these products within the same commerce experience.
After indexing the newly acquired product lines to support the unified index structure (and completing the data normalization steps to see the product lines within the current field structures), you now want to promote this new product line for a specific time period.
The Coveo Relevancy Platform provides businesses with no-code required methods to promote, build new relevancy AI models, and align terminology (synonyms) across the various product lines.
The Coveo Index is separate from the business logic and AI models that are used within the relevancy algorithms. Thus when the newly acquired product line is promoted, the AI models will quickly learn what fields within the new indexed source systems are important to relevancy and boost these fields. This doesn’t require modifying either the new source system or the unified index fields structure.
Importance of User Behavioral Signals
A well-structured index is only one piece of the puzzle. A unified index allows a shopper to easily find what they’re looking for, but it’s of no use if the shopper doesn’t know what’s available. This is where intent comes in.
To determine intent, Coveo captures user behavioral signals. This includes including what the person types or retypes in a query term, what they eventually click or don’t click, and data such as the location they log in from and the time of day/year.
These signals are used to guide the shopper’s buying journey and personalize experiences through suggestions, search engine results and recommendations.
Historic vs In-session Data
The behavioural data used to personalize experiences can be historic or real-time. Historic data trains machine learning models on what others have done or, if the person has a profile, what this shopper has done before. For frequent visitors, the platform can collect information about the user every time they log in, getting to know them really well over time.
History-based personalization is a great way to create relevant digital experiences. It can be compared to coming into a neighborhood store where they know you so well that you barely need to say anything to be offered the exact item you’re looking for.
However, the reality for most ecommerce sites is such that most users, even if they create a profile, don’t visit enough times for the system to gather enough historic data on them. We call these cold-start shoppers.
A lack of knowledge of your customer doesn’t mean you can’t still provide a great personalized experience. Coveo uses both historic and real-time data to determine intent. In-session personalization relies on real-time data that informs the machine of what a person is doing within a session.
In-session personalization can be compared to entering a newly opened corner store where nobody knows you but whose salespeople are so attuned to your needs and committed to treating you as an individual that you feel listened to and respected.
Session-based Personalization
To create a personalized shopping experience based on real-time information, Coveo employs a user profile service that feeds both historic and in-session data into the machine learning models. To do that, we use a model called prod2vec, which plots products in a three-dimensional environment, looking at the relationship between each.
In-session personalization means gaining insight from every action your shopper takes on your site to learn more about what they’re looking for. Every click and keyword query is used to shape their experience, bringing them to the right outcome faster.
Time and location
Right from the start the system can begin to personalize the content based on where the person logs in from. So, for example, if it’s December and they log into a sports gear website from New Zealand, they might be shown surfing gear. But if they log in from New York at the same time of year, they’ll be shown ski gear.
Dynamic facets and filters
Faceted search means helping the user narrow down their search results using multiple dimensions, or facets, to get to the desired item or product. For example, if they search for “women’s dresses,” they’ll be prompted to select “style,” “price,” and “size” to narrow down the results on the consequent SERP.
Dynamic facets and filters means the system takes cues from the user’s behaviour when presenting them with results. For instance, if the user’s search query is “square table,” they shouldn’t see or have to apply a filter for “shape” as the system should understand their intent and return a list of tables in the desired shape.
Enhanced product data in combination with advanced NLP capabilities is what allows the system to find products in the same way people think about them.
Discovery tags
Discovery tags are used to help narrow down the search of users who login more often on mobile. Since it’s difficult to display both filters and results at the same time on a small screen, discovery tags are used instead to guide the buying journey.
If a user types in a generic search term such as “shoes” and it’s their first query so the system doesn’t know anything about their interests yet, it will try help them narrow down the search by presenting them with quick filter tags such as “running,” “casual,” “formal,” etc.
User clustering
Using refined similarity models, the system tries to predict user affinities based on their topics of interest and affiliations that become apparent as they browse. For instance, after a few queries the system might be able to figure out that a shopper is an urban professional who enjoys mountain biking on weekends.
This is possible even for one-time users who are not logged in: in this case, instead of adding the data to a persistent user profile, the system assigns the user a temporary user ID that expires when they leave the session.
Conclusion
Without a doubt, a properly structured, search engine index plays an essential role in an ecommerce shopping experience. But understanding inventory – without intent leaves you wanting. Incorporating user signals with your unified index will provide that one-two punch. The advanced NLP capabilities of a well-oiled AI-powered system will enable easy deciphering of a user’s intent. And provide personalized and relevant resukts.
Dig Deeper
Looking for a new ecommerce search engine solution, but not sure where to start? Here are six questions to ask yourself (and vendors!) when evaluating all of the available options.